How do you feel about researchers tracking your mood using technology? How about tracking your physical activity or your sleep? How much technology will we let into our lives in the name of research?
These were the questions being asked this summer, when a team of researchers (from Bristol, Manchester, London and Oslo) went to speak to members of the public. They took the University of Bristol’s mobile lab around the city of Bristol and surrounding areas, to festivals, community groups and local parks. They wanted to understand public perceptions towards the use of technology to monitor mood and behaviour throughout the day, whether or not this was acceptable, and how to involve a diverse group of people in their research. In this blog post they tell us about what they did and what they found out. (more…)
Gemma Sharp and Flo Martin reflect on the importance of engaging with men, as well as women, when it comes to public engagement about menstruation and pregnancy research(more…)
On 20-21 July we will be welcoming people to Bristol and online around the world to our Mendel at 200 conference. For those who will be joining us face-to-face, there is an opportunity to visit the historic Bristol Zoo Gardens. George Davey Smith shares the story of some of the early zoo residents and how they relate to Mendel’s discoveries.(more…)
In the first of a series of blog posts celebrating 200 years since the birth of Gregor Mendel, Lavinia Paternoster shares how learning about genetics at school shaped her future career – and introduces us to a cat called Mendel(more…)
Neil Davies discusses a new paper on a genome-wide association study of almost 180,000 siblings and discusses what additional insight siblings bring to such studies.(more…)
In the 1970s two randomised trials of aspirin led by Professor Peter Elwood from the MRC Epidemiology Unit, South Wales made the headlines for finding that a low dose of aspirin had beneficial effects for patients who had had a heart attack.
This was just one of many important discoveries from over 50 years of epidemiological research carried out in South Wales in MRC units, including the Epidemiology Unit initially directed by Archie Cochrane, and then by Peter Elwood. (more…)
On Wednesday 7th July 2021, I brought together key stakeholders with an interest in improving opioid substitution treatment (OST) from across the UK. This included people with lived experience, Public Health England staff, local authority public health practitioners, treatment service leads, pharmacists and academics. We discussed the findings of my recently completed PhD, and together we considered the next stages of developing an intervention to improve OST.
A summary of my research
For those not familiar with the topic, OST refers to the treatment of opioid dependency with either methadone or buprenorphine (alongside psychosocial support). Through my research, I wanted to understand what the key facilitators and barriers are to people ‘recovering’ in OST. To do this, I drew on both quantitative and qualitative methodologies. I found that loneliness, isolation and experiences of trauma and stigma were key barriers to recovery; whereas positive social support, discovering a sense of purpose and continuity of care were valuable facilitators.
Importantly, some factors appear to act as both facilitators and barriers to recovery in OST. For instance, I found that some service users used isolation as a form of self-protection (to shield themselves from negative influences), however this often left them feeling lonely and disconnected from the potential benefits offered by developing more positive social support networks.
Undoubtedly, the strongest barrier to recovery was stigma. Service users told me that they experience stigma from a range of sources, including from family and friends, healthcare professionals and members of the wider community. I found similar patterns in the literature review that I carried out (Carlisle et al, 2020). Stigma is like a stain where an individuals’ entire identity is defined by a single, negative attribute. In the case of OST, individuals may possess overlapping stigmatised identities of ‘OST service user’, ‘drug user’ and ‘injecting drug user’. Some will be further stigmatised due to experiencing homelessness, being HIV or Hepatitis C positive or through involvement in sex-work.
“I found that loneliness, isolation and experiences of trauma and stigma were key barriers to recovery”
Community pharmacies are one environment where service users report experiencing a great deal of stigma. Unlike customers collecting other prescriptions, many OST service users receive their medications (methadone/buprenorphine) through an arrangement known as ‘supervised consumption’. This means they must be observed taking their medication by a pharmacist to ensure that it is not diverted to others. This is often conducted in full view of other customers, despite guidelines which recommend that this takes place in a private room or screened area. This leaves OST service users open to the scrutiny of the ‘public gaze’.
My findings have several implications in relation to stigma. Firstly, OST service users receive poorer care than other members of society in healthcare settings, which may result in them avoiding seeking help from drug treatment and for other health conditions. Secondly, stigmatising OST service users makes community re-integration extremely challenging and this has been directly linked to individuals returning to drug using networks as it is somewhere they feel a sense of belonging. The ultimate impact of being repeatedly exposed to stigma is an internalisation of these judgements, resulting in feelings of shame and worthlessness – again impacting on individuals’ ability to seek help and develop supportive new relationships with others.
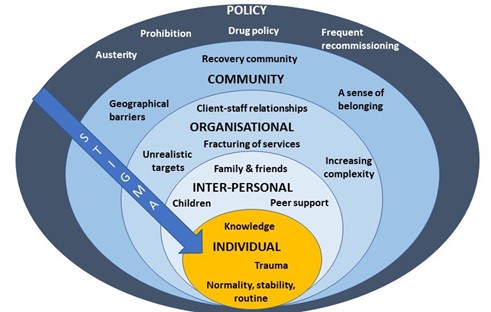
Figure 1: Key facilitators and barriers to recovery, retention and completion in OST at each level of the socioecological model. Stigma is present at every level of the system.
What we discussed during the workshop
Being able to present these findings to key stakeholders was a real highlight of my PhD work; it’s not often that you have the ear of so many invested and engaged individuals in one ‘room’ (albeit a Zoom room!). The findings of my PhD chimed closely with the experiences of those in the room and would be further reflected the next day when Dame Carol Black’s Review of Drugs Part 2 was published, which made specific reference to stigma.
After I presented a short overview of my PhD findings, attendees spent time in small groups discussing how we might address OST stigma at each level of the socioecological system (see figure 1, above). A common thread that ran through each of the groups’ discussions was the importance of embedding interventions within trauma-informed frameworks. Attendees felt that increasing others’ understanding of the impact of trauma and ‘adverse childhood experiences’ (ACEs) may be a key mechanism by which to reduce stigma towards OST service users.
Indeed, a recent study found promising results in relation to this – that increasing the public’s awareness of the role of ACEs in substance use reduced stigmatising attitudes towards people who use drugs (Sumnall et al, 2021). Workshop attendees suggested that this outcome could be achieved through trauma-informed training of all individuals who might work with OST service users, such as pharmacists, the police and medical professionals, as well as those who work in healthcare settings, such as receptionists.
At the individual level there was a discussion about the way that stigma trickles down the socioecological system, resulting in self-stigma or internalised stigma. People felt that the best way to reduce this was to tackle stigma higher upstream first.
When thinking about reducing stigma in everyday inter-personal interactions, people highlighted the importance of using non-stigmatising language. For those who are interested (and I think we all should be!) the Scottish Drug Forum has published an excellent guide here.
Some excellent suggestions were made for reducing stigma that individuals experience in organisations such as pharmacies, hospitals and other settings. This is something that Dr Jenny Scott and I discussed in a recent article for the Pharmaceutical Journal (Scott & Carlisle, 2021). One attendee suggested the introduction of positive role-models within organisations who could be an exemplar of positive behaviour for others (a ‘stigma champion’ perhaps?). Training was identified as a key mechanism through which stigma could be reduced in organisations, including through exposure to people who use drugs (PWUD) and OST service users during training programmes. It was stressed however, that this should be carefully managed to ensure that a range of voices are presented and not just ones supporting dominant discourses around abstinence-based recovery.
Suggestions for improving community integration included increasing access to volunteering opportunities – something that people felt has been impacted by reduced funding to recovery services in recent years. It was also suggested that community and faith leaders could be a potential target for education around reducing stigma and understanding the impact of trauma, as these individuals may be best placed to have conversations about stigma with members of their communities.
Finally, there were some thoughtful discussions around the best way to influence policy to reduce stigma. The importance of showing policymakers the evidence-base from previous successful strategies was highlighted. Something that resulted in a lively debate was the issue of supervised consumption with arguments both for and against (this is also relevant at the organisational level). The group summarised that whilst diversion of medications was a risk for some, a blanket approach to supervised consumption and/or daily collections exposes individuals to stigma in the pharmacy, which leaves individuals vulnerable to dropping out of treatment. It was pointed out that supervised consumption policies were quickly relaxed at the start of Covid-19 restrictions – something that appears to have been done safely and with benefits to service users. It was also highlighted that supervised consumption in OST is inherently stigmatising, as users of other addictive drugs with overdose potential, such as other prescribed opioids and benzodiazepines, are not subjected to the same regulations. This sends a clear message to OST service users that they cannot be trusted. Other key suggestions were:
Communicating with CQCs and Royal Colleges, who may be particularly interested in understanding how people are treated in their services.
Drawing on existing stigma policies from other arenas e.g. mental health.
Highlighting the fiscal benefits of reducing stigma to key decision makers.
Tapping into plans for the new Police and Crime Commissioners, who have a trauma sub-group.
Linking into work with ADDER areas, which may provide the evidence for ‘what works’.
What next?
I am now planning to apply for further funding to develop an intervention to reduce organisational stigma towards OST service users. The involvement of service users and other key stakeholders will be crucial in every step of that process, so I will be putting together a steering group as well as seeking out collaborations with academics internationally that have expertise and an interest in this area. I was really pleased to see that Dame Carol Black’s second report makes some concrete recommendations around reducing stigma towards people who use drugs. I hope therefore to be able to work with the current momentum to make OST safer and more attractive to those whose lives depend on it.
I’d like to extend my gratitude to all of the attendees at the workshop and to Bristol’s Drug and Alcohol Health Integration Team (HIT) for supporting this event. If you are an individual with lived experience of OST, an academic, or any other stakeholder working in this area and would like to be involved with future developments, please get in touch with me at vicky.carlisle@bristol.ac.uk or find me on Twitter at @Vic_Carlisle.
References
Carlisle, V., Maynard, O., Padmanathan, P., Hickman, M., Thomas, K. H., & Kesten, J. (2020, September 7). Factors influencing recovery in opioid substitution treatment: a systematic review and thematic synthesis. https://doi.org/10.31234/osf.io/f6c3p
Sumnall, H. R., Hamilton, I., Atkinson, A. M., Montgomery, C., & Gage, S. H. (2021). Representation of adverse childhood experiences is associated with lower public stigma towards people who use drugs: an exploratory experimental study. Drugs: Education, Prevention and Policy, 28(3), 227-239. https://doi.org/10.1080/09687637.2020.1820450
This blog was originally posted on the TARG blog on the 1 October 2021.
Drs Luisa Zuccolo and Cheryl McQuire, Department of Population Health Sciences, Bristol Medical School, University of Bristol.
The problem
Soon after the World Health Organisation (WHO) declared COVID-19 a pandemic on March 11th 2020, the UN declared the start of an infodemic, highlighting the danger posed by the fast spreading of unchecked misinformation. Defined as an overabundance of information, including deliberate efforts to disseminate incorrect information, the COVID-19 infodemic has exacerbated public mistrust and jeopardised public health.
Social media platforms remain a leading contributor to the rapid spread of COVID-19 misinformation. Despite urgent calls from the WHO to combat this, public health responses have been severely limited. In this project, we took steps to begin to understand and address this problem.
We believe that it is imperative that public health researchers evolve and develop the skills and collaborations necessary to combat misinformation in the social media landscape. For this reason, in Autumn 2020 we extended our interest in public health messaging, usually around promoting healthy behaviours during pregnancy, to study COVID-19 misinformation on social media.
We wanted to know:
What is the nature, extent and reach of misinformation about face masks on Twitter during the COVID-19 pandemic?
To answer this question we aimed to:
Upskill public health researchers in the data capture and analysis methods required for social media data research;
Work collaboratively with Research IT and Research Software Engineer colleagues to conduct a pilot study harnessing social media data to explore misinformation.
The team
Dr Cheryl McQuiregot the project funded and off the ground. Dr Luisa Zuccolo led it through to completion. Dr Maria Sobczykchecked the data and analysed our preliminary data. Research IT colleagues, led by Mr Mike Jones, helped to develop the search strategy and built a data pipeline to retrieve and store Twitter data using customised application programming interfaces (APIs) accessed through an academic Twitter account. Research Software Engineering colleagues, led by Dr Christopher Woods, provided consultancy services and advised on the analysis plan and technical execution of the project.
Cheryl McQuire, Luisa Zuccolo, Maria Sobcyzk, Mike Jones, Christopher Woods. (Left to Right)
Too much information?!
Initial testing of the Twitter API showed that keywords, such as ‘mask’ and ‘masks’, returned an unmanageable amount of data, and our queries would often crash due to an overload of Twitter servers (503-type errors). To address this, we sought to reduce the number of results, while maintaining a broad coverage of the first year of the pandemic (March 2020-April 2021).
Specifically, we:
I) Searched for hashtags rather than keywords, restricting to English language.
II) Requested original tweets only, omitting replies and retweets.
III) Broke each month down into its individual days in our search queries to minimise the risk of overload.
IV) Developed Python scripts to query the Twitter API and process the results into a series of CSV files containing anonymised tweets, metadata and metrics about the tweets (no. of likes, retweets etc.), and details and metrics about the author (no. of followers etc.).
V) Merged data into a single CSV file with all the tweets for each calendar month after removing duplicates.
What did we find?
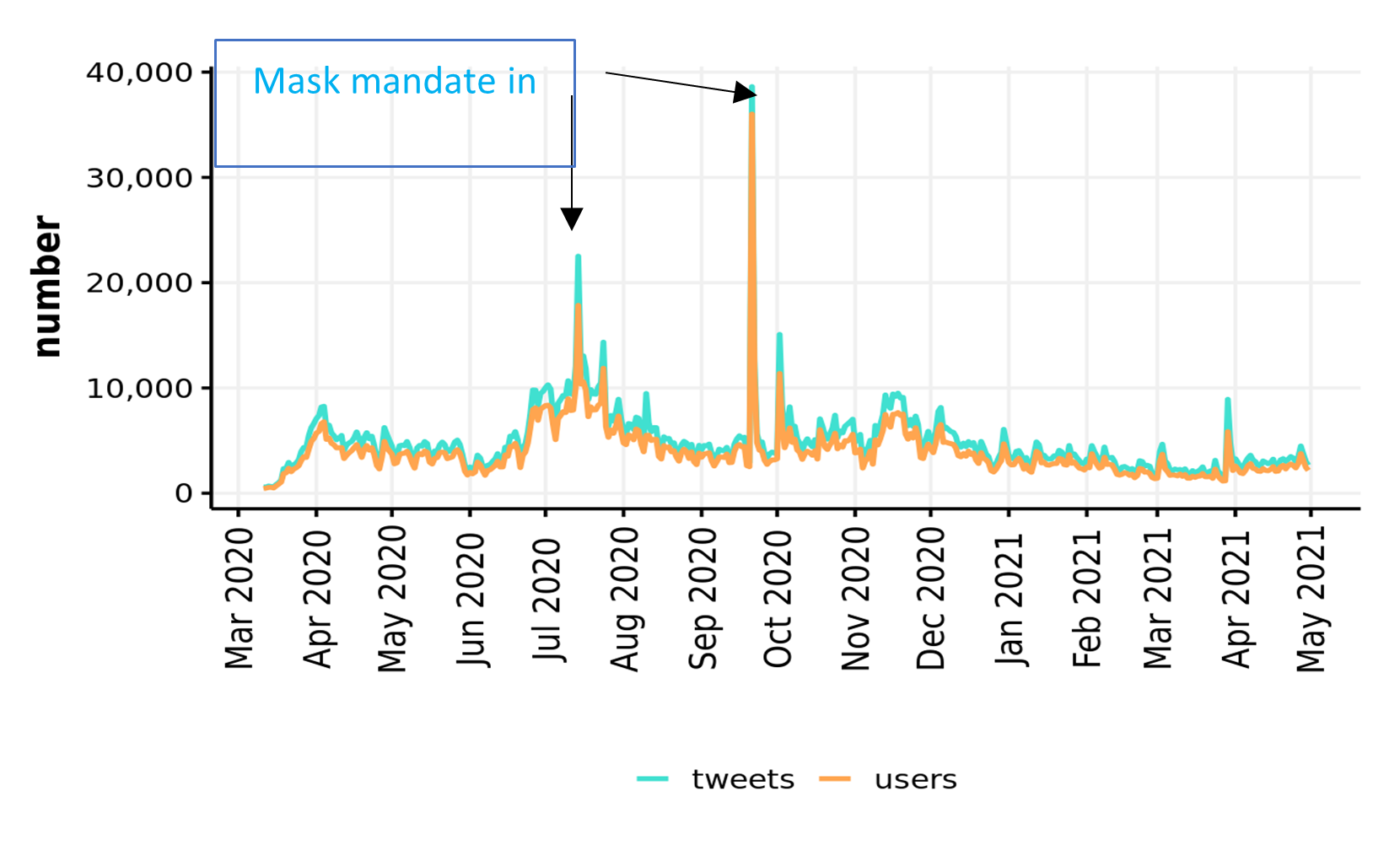
Our search strategy delivered over three million tweets. Just under half of these were filtered out by removing commercial URLs and undesired keywords, the remaining 1.7m tweets by ~700k users were analysed using standard and customized R scripts.
First, we used unsupervised methods to describe any and all Twitter activity picked up by our broad searches (whether classified as misinformation or not). The timeline of this activity revealed clear peaks around the UK-enforced mask mandates in June and September 2020.
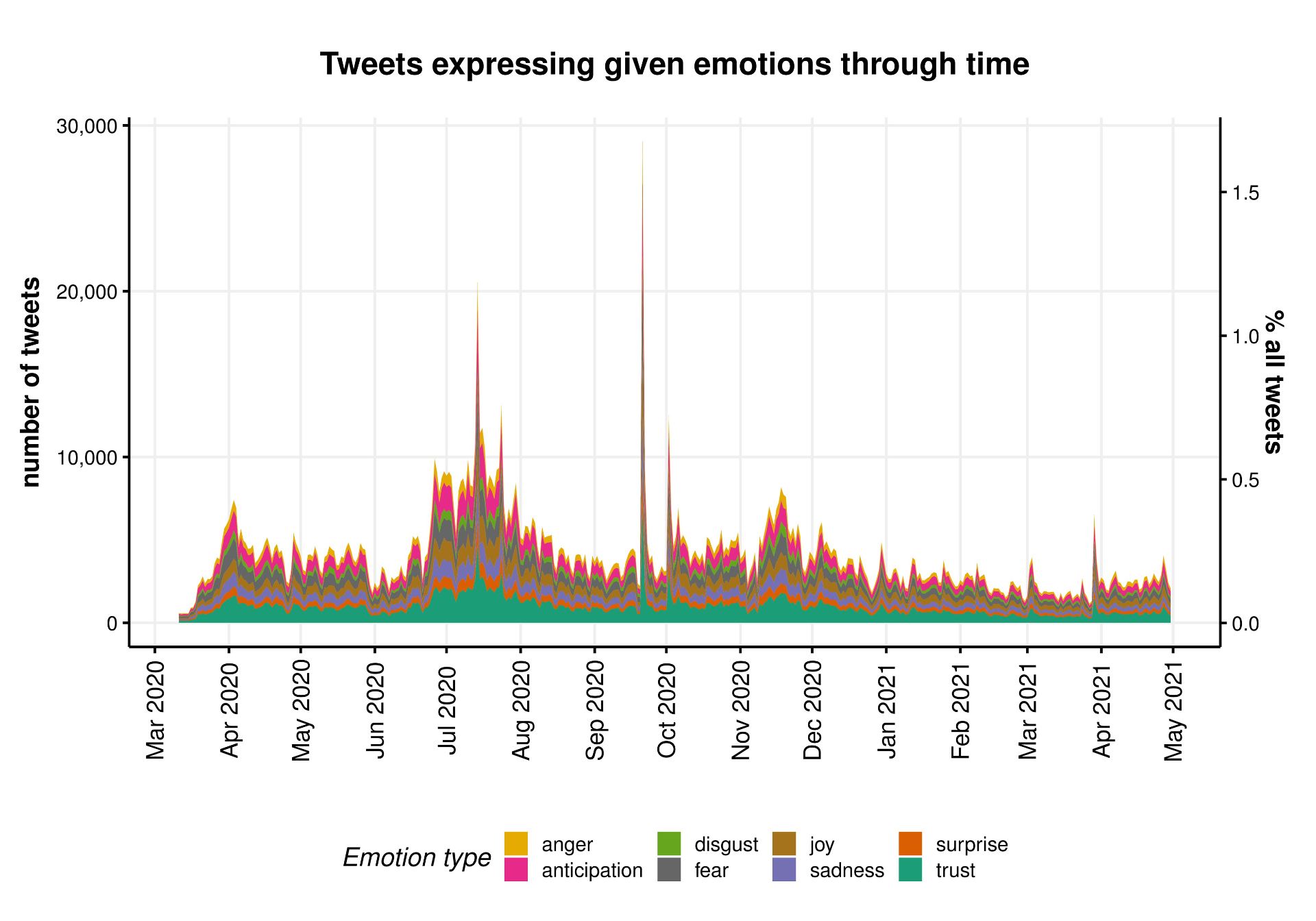
We further described the entire corpus of tweets on face masks by mapping the network of its most common bigrams and performing sentiment analysis.
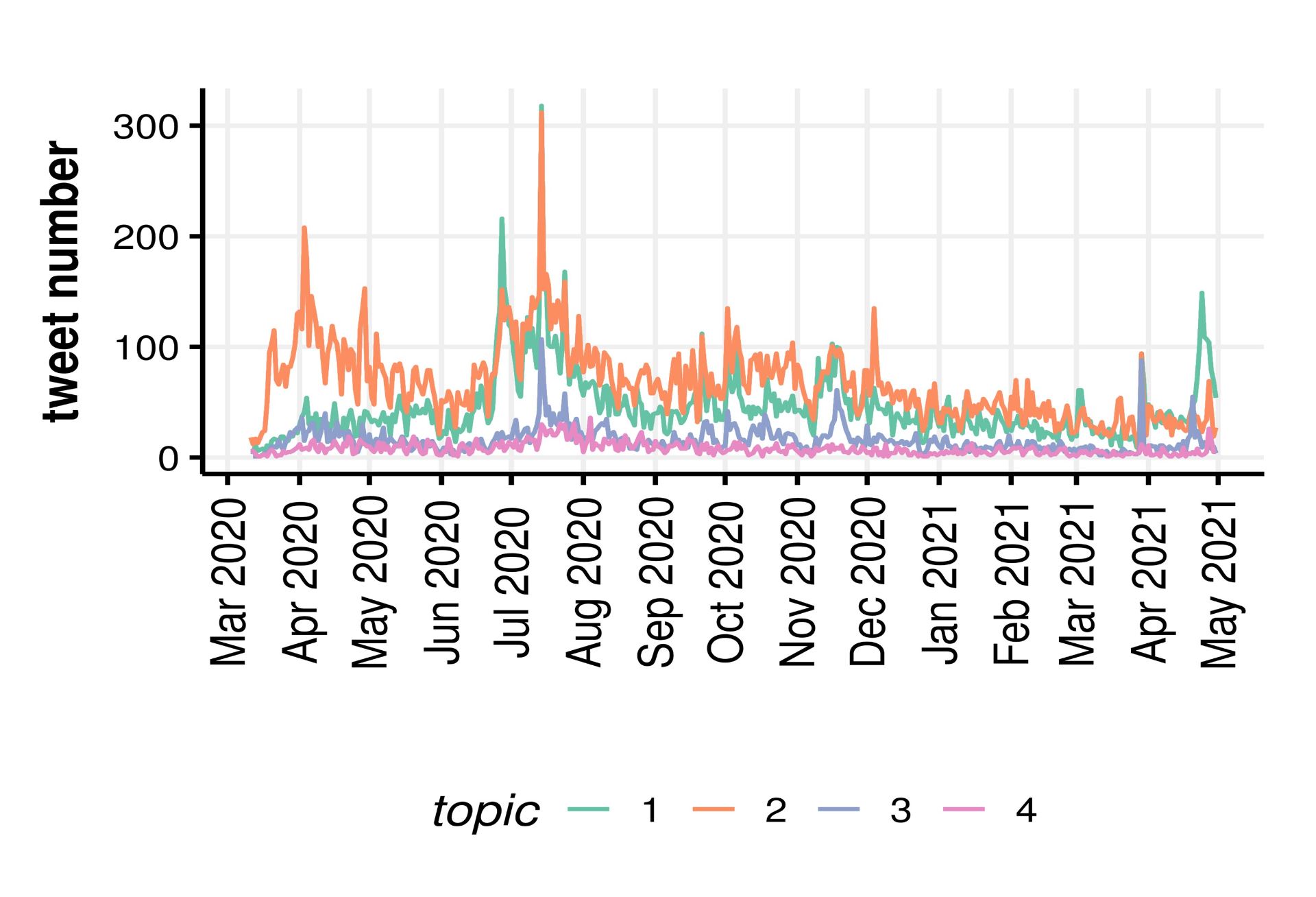
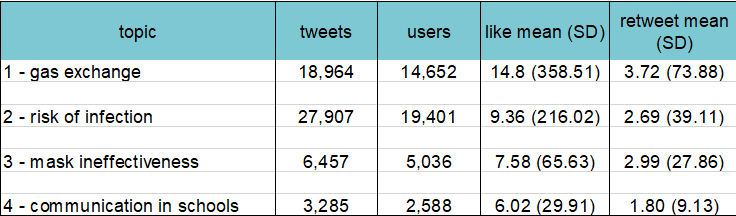
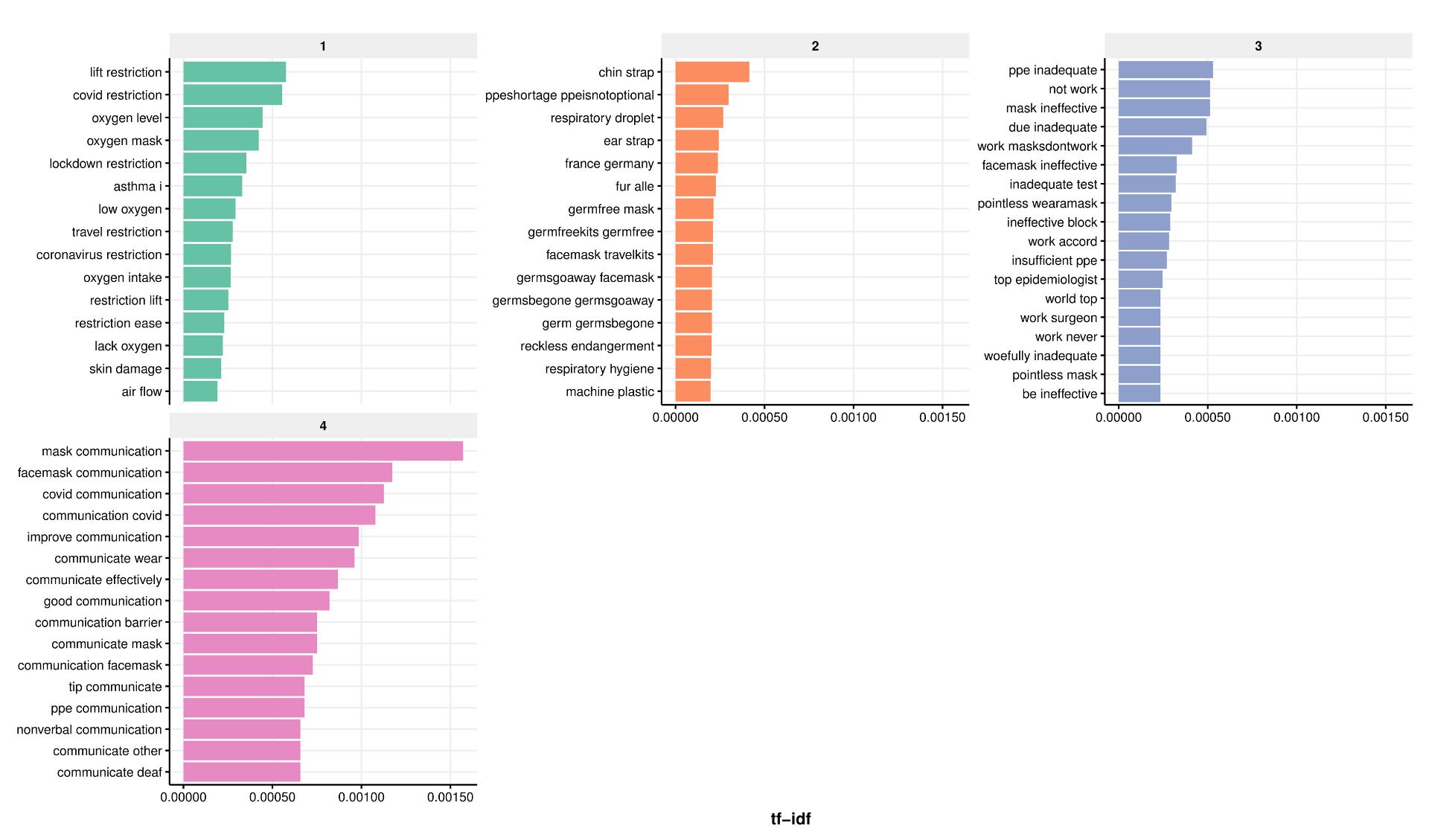
We then quantified the nature and extent of misinformation through topic modelling, and used simple counts of likes to estimate the reach of misinformation. We used semi-supervised methods including manual keyword searches to look for established types of misinformation such as face masks restricting oxygen supply. These revealed that the risk of bacterial/fungal infection was the most common type of misinformation, followed by restriction of oxygen supply, although the extent of misinformation on the risks of infection decreased as the pandemic unfolded.
Extent of misinformation (no tweets), according to its nature: 1- gas exchange/oxygen deprivation, 2- risk of bacterial/fungal infection, 3- ineffectiveness in reducing transmission, 4- poor learning outcomes in schools.
Relative to the volume of tweets including the hashtags relevant to face masks (~1.7m), our searches uncovered less than 3.5% unique tweets containing one of the four types of misinformation against mask usage.
A summary of the nature, extent and reach of misinformation on face masks on Twitter – results from manual keywords search (semi-supervised topic modelling).
A more in-depth analysis of the results attributed to the 4 main misinformation topics by the semi-supervised method revealed a number of potentially spurious topics. Refinements of these methods including iterative fine-tuning were beyond the scope of this pilot analysis.
Our initial exploration of Twitter data for public health messaging also revealed common pitfalls of mining Twitter data, including the need for a selective search strategy when using academic Twitter accounts, hashtag ‘hijacking’ meaning most tweets were irrelevant, imperfect Twitter language filters and ads often exploiting user mentions.
Next steps
We hope to secure further funding to follow-up this pilot project. By expanding our collaboration network, we aim to improve the way we tackle misinformation in the public health domain, ultimately increasing the impact of this work. If you’re interested in health messaging, misinformation and social media, we would love to hear from you – @Luisa_Zu and @cheryl_mcquire.
In two-sample Mendelian randomization (MR), a type of epidemiological method, we combine the results from different genetic studies to study the causal relationship between human characteristics and disease. For example, we might take results from a genetic study of smoking and a different genetic study of cancer. We can combine their results to understand whether smoking might be a cause of cancer. If the same position in the genome is associated with smoking in the first study and with cancer in the other study, this can provide evidence that smoking is a causal factor in cancer. However, it’s also possible that this position in the genome could be related to smoking and cancer via separate pathways. This phenomenon is known as “horizontal pleiotropy” and is a common source of bias in Mendelian randomization research.
Another, often under-appreciated, source of bias are errors in metadata. To understand this we need to understand what genetic results look like in practice. Below is an example of a genetic results file with 5 rows and 6 columns (a typical file might actually have several million rows).
Example of genetic results
Each row refers to a single position in the human genome that varies between people. These positions are referred to as “genetic variants” (also known as polymorphisms). The particular type of variant that an individual carries is known as their allele.
Below is an example of metadata. The metadata helps us understand the contents of the results file. It tells us what the columns represent.
Example of metadata
Some columns in the results file will describe the relationship (“effect” column) between the genetic variant and some human characteristic (e.g. smoking) and there will be additional columns that help researchers interpret this relationship. These additional columns include things like the identity of the allele that is used to model the relationship (e.g. if people have allele “A” they may be more likely to smoke compared to people without this allele) or information on how common the allele is in the population. These columns are also known as the “effect allele” and “effect allele frequency” columns. Metadata errors refer to mistakes in how these columns are reported. For example, maybe allele1 is reported as the effect allele column when in fact it should have been allele 2 that is described in this way. Sometimes the information provided in metadata is ambiguous. For example, the metadata tells us that the “freq” column represents allele frequency but there are two alleles. Is this the frequency of allele1 or allele2? We can’t be sure. Another type of error refers to mistakes in the reported results, for example reporting that a genetic variant increases the probability that a person smokes when in reality it has no effect (in other words the effect is zero). This is known as a summary data error. Failure to identify these errors can lead to mistakes in Mendelian randomization analyses, such as finding that smoking protects against cancer (when we know the opposite is true).
As research complexity increases, so does the potential for errors
These types of errors were fairly easy to avoid during the early years of Mendelian randomization research, when studies tended to be hypothesis-driven and focused on small numbers of relationships (although errors still occurred). Mendelian randomization study designs are, however, increasingly complex and hypothesis-free, sometimes assessing relationships amongst 100s or even 1000s of characteristics and diseases. New online platforms and databases that collate genetic results from many different sources, and provide tools that can automate analyses, make these studies easier to undertake than ever before. The downside is that they probably make meta and summary data errors more likely.
Maximising metadata quality to reduce errors
We address this issue in a new pre-print: “Design and quality control of large scale Mendelian randomization studies”. We present an R package and set of quality control tools that identify meta and summary data errors, which we developed for the Fatty Acids in Cancer Mendelian Randomization Collaboration (FAMRC). The FAMRC is a pan-cancer MR study that seeks to evaluate the causal relevance of fatty acids for risk of major cancers. We wanted to maximise the quality of the genetic study results we collected from the cancer studies, to ensure the integrity of our Mendelian randomization analyses. After implementing our tools, we found major meta and summary data errors in 7 (13%) of 55 genetic studies in the FAMRC.
What types of metadata errors did we find?
The basic principle of our quality control approach is to identify errors through
comparison of the results of individual studies in the FAMRC to external studies
comparison of reported to expected results.
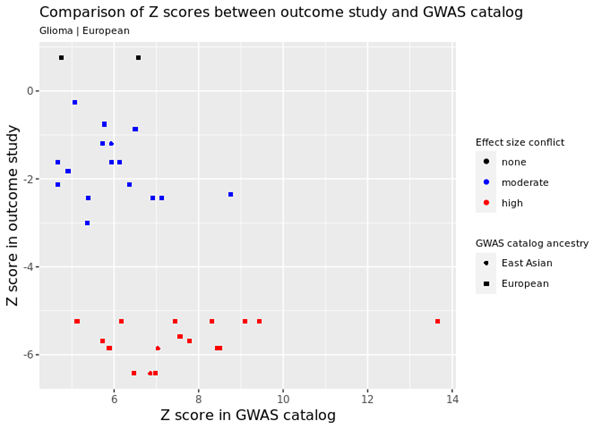
For example, we identified genetic variants that are known to cause cancer and checked that the same variants had the expected relationship in the FAMRC. In the figure below, every data point represents a single genetic variant that is known to increase cancer risk. The horizontal or X axis shows the known relationship in the GWAS catalog (this is a database of known genetic associations with 1000s of human characteristics in 1000s of genetic studies) and the vertical or Y axis shows the relationship in one of the studies in the FAMRC. Each axis shows the Z score, which is basically a standardised measure of how each genetic variant affects cancer risk (positive values mean that the variant increases risk of cancer and negative values indicate they decrease risk). As you can see, in the FAMRC study on the vertical Y axis, almost all the variants have negative Z values (indicating they reduce cancer risk), when in fact they are known to increase risk (the true relationship is represented by Z scores in the GWAS catalog). This discrepancy was caused by a metadata error, where the effect allele column was incorrectly labelled. We also found that the “frequency of the effect allele” was wrong. How common the allele is in the population was opposite to what we’d expect, based on comparison with other studies, confirming the presence of metadata errors.
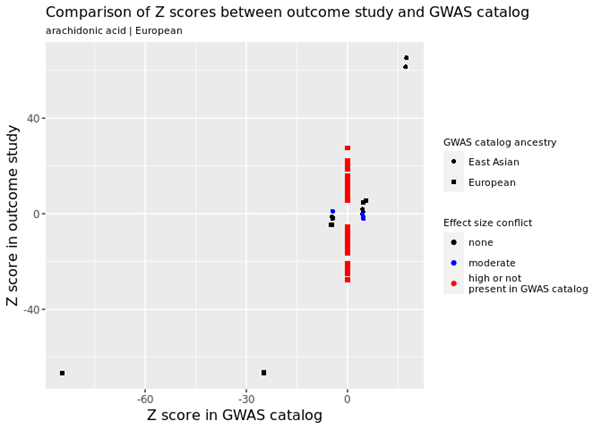
Various other types of errors were identified, including one study reporting that 100s of genetic variants had very strong effects on fatty acid levels when in fact they had no effect at all. For example, in the figure below, the many red data points refer to genetic variants in the FAMRC that had a very large effect on fatty acids but were not reported in the GWAS catalog, suggesting a potential problem with the genetic results.
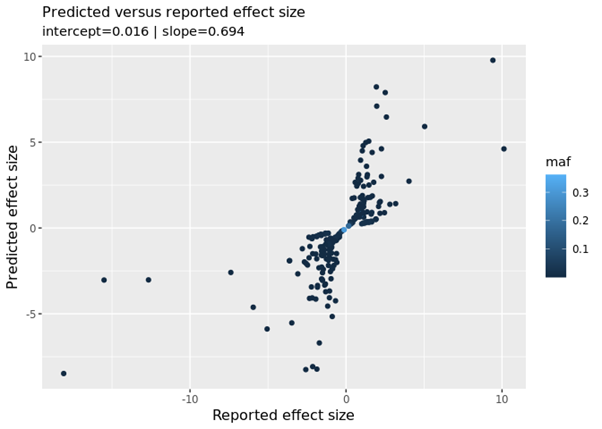
We also compared the reported results (how the genetic variants affected fatty acids in the FAMRC) to predicted results (how we would expect the genetic variants to affect fatty acids). In the figure below we see a “fanning-out” pattern, when what we should see is a strong linear relationship (i.e. the data points lying on a single straight line). This relationship can be summarised with the “slope” metric. We should see a slope of 1 (this means if the reported result increases by 1 the predicted result will also increase by 1), which is not the case. We confirmed with the data provider that low quality genetic variants had not been excluded from their study. Once the low quality variants had been excluded, the discrepancies disappeared.
Avoiding metadata errors: recommendations for researchers
When conducting Mendelian randomization analyses using results from genetic studies, researchers can avoid metadata and other errors by:
Requesting results for genetic variants that are known to affect their disease of interest. Researchers should check that these variants have the expected effect in their dataset.
Comparing the frequency of genetic variants to expected frequencies in a reference dataset. We created a special reference dataset that can be used for this purpose (accessible via the CheckSumStats R package).
Not assuming that results have had low quality variants excluded, but instead seeking confirmation of this with data providers. Our quality control tools also provide a way to check this.
Further attention is needed to address the growing diversity of GWAS
One issue we only partly addressed was the “two-sample assumption”: that the studies being compared come from the same population. In our own analyses, we found that the frequency of genetic variants was very similar across European-origin studies, indicating satisfaction of the assumption. On the other hand, our tools were not really optimised for this purpose. The need to assess the “same population” assumption is becoming more urgent with the growing diversity of genetic studies.
In conclusion, meta and summary data errors are an under-appreciated source of bias in MR research, especially in complex study designs. We developed an R package and set of tools that can be used to flag meta and summary data errors in the results of genetic studies, which in turn can be used to enhance the integrity of Mendelian randomization analyses. Our tools and methods are available to other researchers via the CheckSumStats R package.
Further reading
Design and quality control of large-scale two-sample Mendelian randomisation studies
There’s a widespread belief that your testosterone can affect where you end up in life. At least for men, there is some evidence for this claim: several studies have linked higher testosterone to socioeconomic success. But a link is different to a cause and using DNA, our new research suggests it may be much less important for life chances than previously claimed.
In previous studies, male executives with higher testosterone have been found to have more subordinates, and financial traders with higher testosterone found to generate greater daily profits. Testosterone has been found to be higher among more highly educated men, and among self-employed men, suggesting a link with entrepreneurship. Much less is known about these relationships in women, but one study suggested that for women, disadvantaged socioeconomic position in childhood was linked to higher testosterone later in life.
The beneficial influence of testosterone is thought to work by affecting behaviour: experiments suggest that testosterone can make a person more aggressive and more risk tolerant, and these traits can be rewarded in the labour market, for instance in wage negotiations. But none of these studies show definitively that testosterone influences these outcomes because there are other plausible explanations.
Rather than testosterone influencing a person’s socioeconomic position, it could be that having a more advantaged socioeconomic position raises your testosterone. In both cases, we would see a link between testosterone and social factors such as income, education and social class.
There are plausible mechanisms for this too. First, we know that socioeconomic disadvantage is stressful, and chronic stress can lower testosterone. Second, how a person perceives their status relative to others in society might influence their testosterone: studies of sports matches, usually between men, have often found that testosterone rises in the winner compared to the loser.
Chronic stress can lower your testosterone. Shutterstock
It’s also possible that some third factor is responsible for the associations seen in previous studies. For instance, higher testosterone in men is linked to good health – and good health may also help people succeed in their careers. A link in men between testosterone and socioeconomic position could therefore simply reflect an impact of health on both. (For women, higher testosterone is linked to worse health, so we would expect an association of higher testosterone and lower socioeconomic position.)
Look at it this way
It is very difficult to pick apart these processes and study just the effects of testosterone on other things. With this goal in mind, we applied a causal inference approach called “Mendelian randomisation”. This uses genetic information relevant to a single factor (here, testosterone) to isolate just the effect of that factor on one or more outcomes of interest (here, socioeconomic outcomes such as income and educational qualifications).
DNA can tell us a lot about our relationship with testosterone. Zita/Shutterstock
A person’s circulating testosterone can be affected by environmental factors. Some, like the time of day, are straightforward to correct for. Others, like somebody’s health, are not. Crucially, socioeconomic circumstances could influence circulating testosterone. For this reason, even if we see an association between circulating testosterone and socioeconomic position, we cannot determine what is causing what.
This is why genetic information is powerful: your DNA is determined before birth and generally does not change during your lifetime (there are rare exceptions, such as changes which occur with cancer). Therefore, if we observe an association of socioeconomic position with genetic variants linked to testosterone, it strongly suggests that testosterone is causing the differences in socioeconomic outcomes. This is because influence on the variants of other factors is much less likely.
In more than 300,000 adult participants of the UK Biobank, we identified genetic variants linked to higher testosterone levels, separately for men and women. We then explored how these variants were related to socioeconomic outcomes, including income, educational qualifications, employment status, and area-level deprivation, as well as self-reported risk-taking and overall health.
Similar to previous studies, we found that men with higher testosterone had higher household income, lived in less deprived areas, and were more likely to have a university degree and a skilled job. In women, higher testosterone was linked to lower socioeconomic position, including lower household income, living in a more deprived area, and lower chance of having a university degree. Consistent with previous evidence, higher testosterone was associated with better health for men and poorer health for women, and more risk-taking for men.
However, there was little evidence that genetic variation related to testosterone affected socioeconomic position at all. In both men and women we detected no effects of genetic variants related to testosterone on any aspect of socioeconomic position, or health, or risk-taking.
Because we identified fewer testosterone-linked genetic variants in women, our estimates for women were less precise than for men. Consequently, we could not rule out relatively small effects of testosterone on socioeconomic position for women. Future studies could examine associations in women using larger, female-specific samples.
But for men, our genetic results clearly suggest that previous studies may have been biased by the influence of additional factors, potentially including the impact of socioeconomic position on testosterone. And our results indicate that – despite the social mythology surrounding testosterone – it may be much less important for success and life chances than earlier studies have suggested.
 These were the questions being asked this summer, when a team of researchers (from Bristol, Manchester, London and Oslo) went to speak to members of the public. They took the University of Bristol’s mobile lab around the city of Bristol and surrounding areas, to festivals, community groups and local parks. They wanted to understand public perceptions towards the use of technology to monitor mood and behaviour throughout the day, whether or not this was acceptable, and how to involve a diverse group of people in their research. In this blog post they tell us about what they did and what they found out. (more…)
These were the questions being asked this summer, when a team of researchers (from Bristol, Manchester, London and Oslo) went to speak to members of the public. They took the University of Bristol’s mobile lab around the city of Bristol and surrounding areas, to festivals, community groups and local parks. They wanted to understand public perceptions towards the use of technology to monitor mood and behaviour throughout the day, whether or not this was acceptable, and how to involve a diverse group of people in their research. In this blog post they tell us about what they did and what they found out. (more…) Gemma Sharp and Flo Martin reflect on the importance of engaging with men, as well as women, when it comes to public engagement about menstruation and pregnancy research
Gemma Sharp and Flo Martin reflect on the importance of engaging with men, as well as women, when it comes to public engagement about menstruation and pregnancy research 


 Dr Philip Haycock
Dr Philip Haycock