Dr Kaitlin H. Wade1,2,3
Dr Kaitlin H. Wade1,2,3
1 Population Health Sciences, Bristol Medical School, University of Bristol, Bristol, BS8 2BN
2 Medical Research Council (MRC-IEU), University of Bristol, Bristol, BS8 2BN
3 Cancer Research UK (CRUK) Integrative Cancer Epidemiology Programme (ICEP), University of Bristol, Bristol, BS8 2BN
The causes of cancer are often preventable
Cancer, a disease that has a profound impact on the lives of individuals all over the world, also has an ever-increasing burden. And yet, evidence indicates that over 40% of all cancers are likely explained by preventable causes. One of the main challenges is identifying so-called ‘modifiable risk factors’ for cancer – aspects of our environment that we can change to reduce the incidence of disease.
The gut microbiome could influence cancer risk
The gut microbiome is a system of microorganisms that helps us digest food, produce essential molecules and protects us against harmful infections. There is growing evidence supporting the relationship between the human gut microbiome and risk of cancer, including lung, breast, bowel and prostate cancers. For example, experiments have shown that changing the gut microbiome (e.g., by using pre- or pro-biotics) may reduce the risk of developing colorectal cancer. Research also suggests that people with colorectal cancer have lower microbiota diversity and different types of bacteria within their gut compared to those without a diagnosis.
As the gut microbiome can have a substantial impact on their host’s metabolism and immune response, there are many biological mechanisms by which the gut microbiome could influence cancer development and progression. However, we don’t yet know how the gut microbiome can do this.
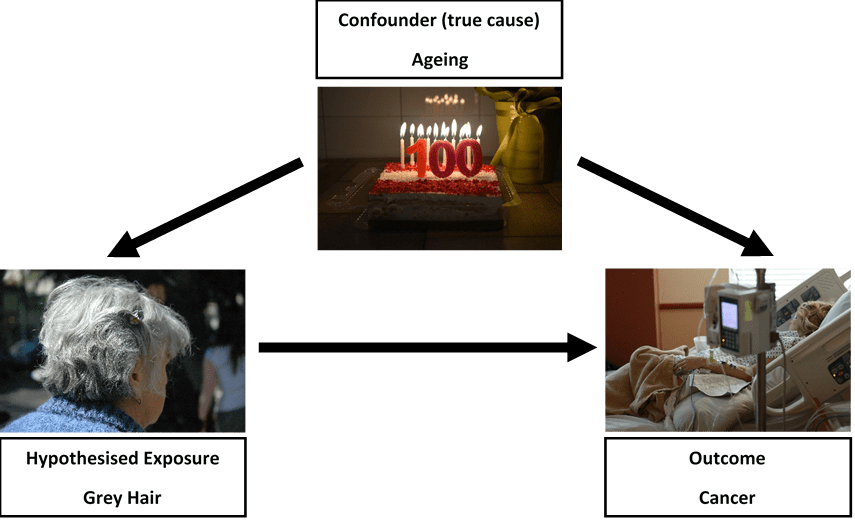
Human studies in this context have used small samples of individuals and measure both the microbiome and disease at the same time. These factors can make it difficult to tease apart correlation from causation – i.e., does variation in the gut microbiome change someone’s risk of cancer or is it the existence of cancer that leads to variation in the gut microbiome? This is an important question because the main aim of such research is to understand the causes of cancer and how we can prevent the disease. We want to fully understand whether altering the gut microbiome can reduce the burden of cancer at a population level or whether it is simply a marker of cancer itself.
I’m inviting feedback on your knowledge and understanding of the gut microbiome and cancer – please take this 5-minute survey (click here for survey) to contribute your thoughts.
People are interested in their gut microbiome
Even though we don’t yet know much about the causal relevance of the gut microbiome, there is still a growing market for commercial initiatives targeting the microbiome as a consumer-driven intervention. This usually involves companies obtaining a small number of faecal samples from consumers and prescribing “personalised” nutritional information for a “healthier microbiome”. However, these initiatives are very controversial given uncertainty in the likely relationships between the gut microbiome, nutrition and various diseases. What these activities do highlight is the demand for such information at a population level. This shows there is an opportunity to improve understanding of the causal role played by the gut microbiome in human health and disease.
Microbiome and variation in our genes
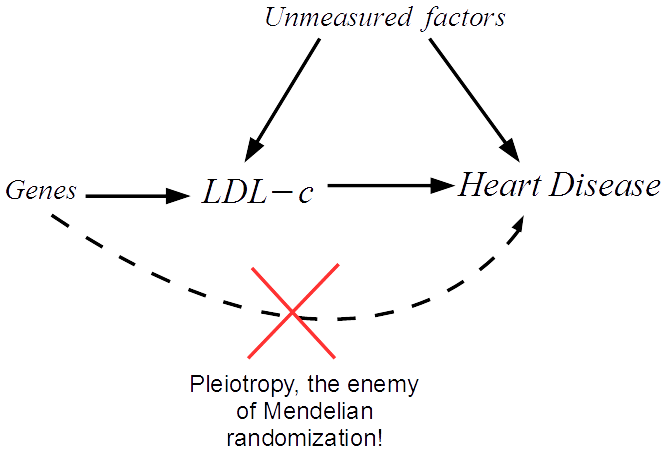
Using information about our genetics can help us find out whether the gut microbiome changes the risk of cancer, or whether cancer changes the gut microbiome. Genetic variation cannot be influenced by the gut microbiome nor disease. Therefore, if people who are genetically predisposed to having a higher abundance of certain bacteria within their gut also have a lower risk of, say, prostate cancer, this would strongly suggest a causal role of those bacteria in prostate cancer development. This approach of using human genetic information to discern correlation from causation is called Mendelian randomization.
Studies relating human genetic variation with the gut microbiome have proliferated in recent years. They have provided evidence for genetic contributions to features of the gut microbiome including the abundance or likelihood of presence (vs. absence) of specific bacteria. This knowledge has given the opportunity to apply Mendelian randomization to better understand the causal impact of gut microbiome variation in health outcomes, including cancer. There are, however, many important caveats and complications to this work. Specifically, there is a (currently unmet) requirement for careful examination of how human genetic variation influences the gut microbiome and interpretation of the causal estimates derived from using Mendelian randomization within this field.
This is exactly what I will be looking at in my new research funded by Cancer Research UK. For more details on the nuances of this work, please see my research feature for Cancer Research UK and paper discussing these complexities.
What’s next for this research?
This research has already shown promise in the application of Mendelian randomization to improve our ability to discern correlation from causation between the gut microbiome and cancer. It has importantly highlighted the need for inter-disciplinary collaboration between population health, genetic and basic sciences. Thus, with the support from my team of experts in microbiology, basic sciences and population health sciences, this Fellowship will set the scene for the integration of human genetics and causal inference methods in population health sciences with microbiome research. This will help us understand the causal role played by the gut microbiome in cancer. Such work acts as a new and important step towards evaluating and prioritising potential treatments or protective factors for cancer prevention.
Acknowledgements
The research conducted as part of this Cancer Research UK Population Research Postdoctoral Fellowship will be supported by the following collaborators: Nicholas Timpson, Caroline Relton, Jeroen Raes, Trevor Lawley, Lindsay Hall and Marc Gunter, and my growing team of interdisciplinary PhD students and postdoctoral researchers. I’d also like to thank the following individuals for comments on this feature: Tom Battram, Laura Corbin, David Hughes, Nicholas Timpson, Lindsey Pike and Philippa Gardom. Additional thanks go to Chloe Russell, a brilliant photographer with whom I collaborated to create “Up Your A-Z” as part of Creative Reactions 2019, who provided the photos for this webpage.
About the author
Dr. Wade’s academic career has focused on the integration of human genetics with population health sciences to improve causality within epidemiological studies. Focusing on relationships across the life-course, her work uses comprehensive longitudinal cohorts, randomized controlled trials and causal inference methods (particularly, Mendelian randomization and recall-by-genotype designs). Kaitlin’s research has focused on understanding the relationships between adiposity and dietary behaviours as risk factors for cardiometabolic diseases and mortality. Having been awarded funding from the Elizabeth Blackwell Institute and Cancer Research UK, Kaitlin’s work uses these methods to understand the causal role played by the human gut microbiome on various health outcomes, such as obesity and cancer. Since pursuing a career in this field, Kaitlin has already led and been key in several fundamental studies that with path the way to resolve – or at least quantify – complex relationships between genetic variation, the gut microbiome and human health. In addition to her research, Kaitlin is actively involved in organising and administering teaching and public engagement activities as well as having many mentorship and supervisory roles within and external to the University of Bristol.
Key publications:
Hughes, D.A., Bacigalupe, R., Wang, J. et al. Genome-wide associations of human gut microbiome variation and implications for causal inference analyses. Nat Microbiol 5, 1079–1087 (2020). https://doi.org/10.1038/s41564-020-0743-8.
Kurilshikov, A., Medina-Gomez, C., Bacigalupe, R. et al. Large-scale association analyses identify host factors influencing human gut microbiome composition. Nat Genet 53, 156–165 (2021). https://doi.org/10.1038/s41588-020-00763-1.
Wade KH and Hall LJ. Improving causality in microbiome research: can human genetic epidemiology help? [version 3; peer review: 2 approved]. Wellcome Open Res 4, 199 (2020). https://doi.org/10.12688/wellcomeopenres.15628.3.