Leaving the EU presents many unique challenges to Britain, among which is the crucial task of maintaining ourhigh levels of food safety. As a submission to the Jean Golding Institute’s data visualisation competition,we briefly investigated the impacts that Brexit mayhave on British food supplies.The dataset used in this analysis was made available by the Food Standards Agency (FSA)as the focus of the competition, and all code used is freely available in ourgithub repository.
The Need for Information Recompense
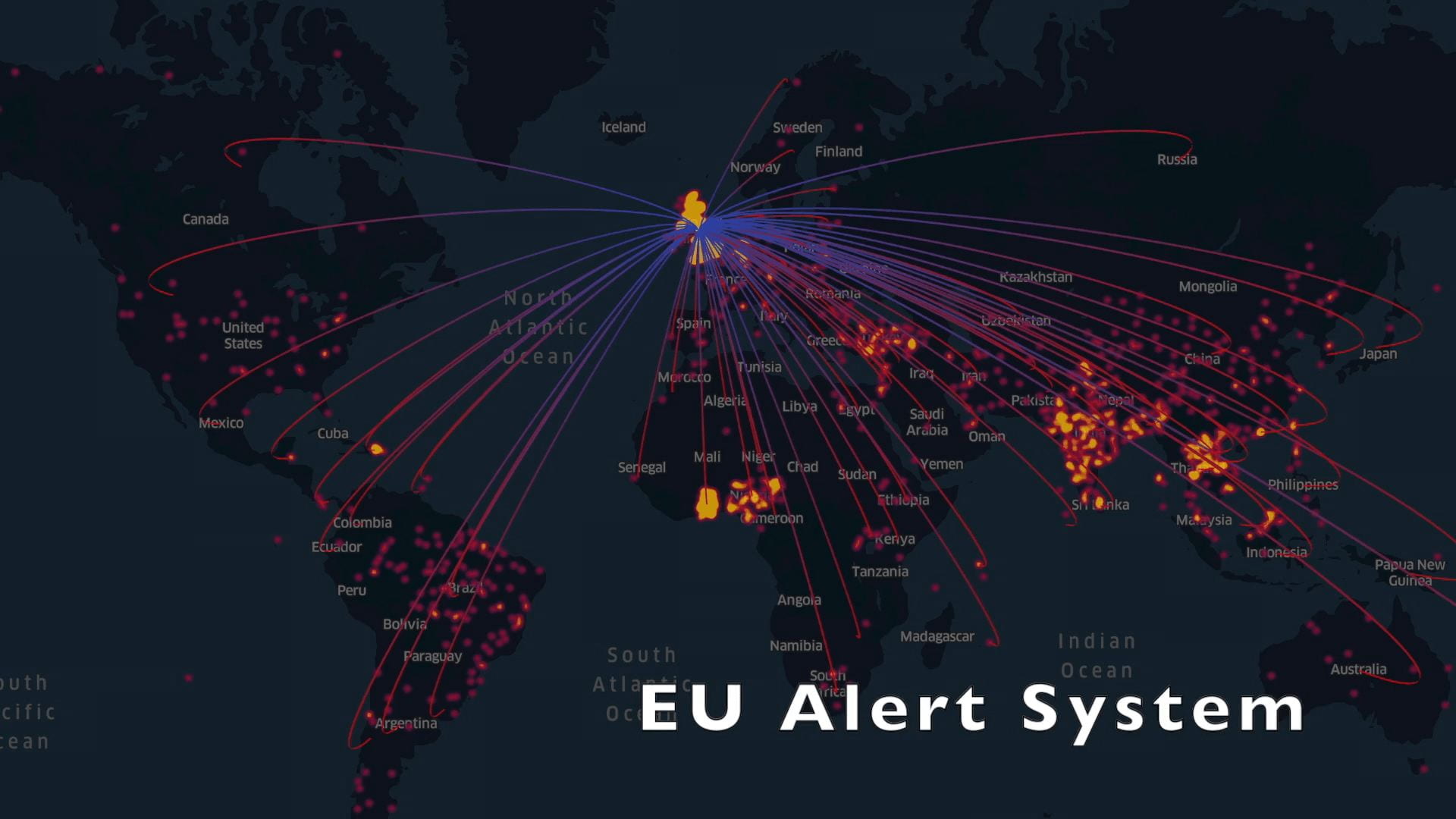
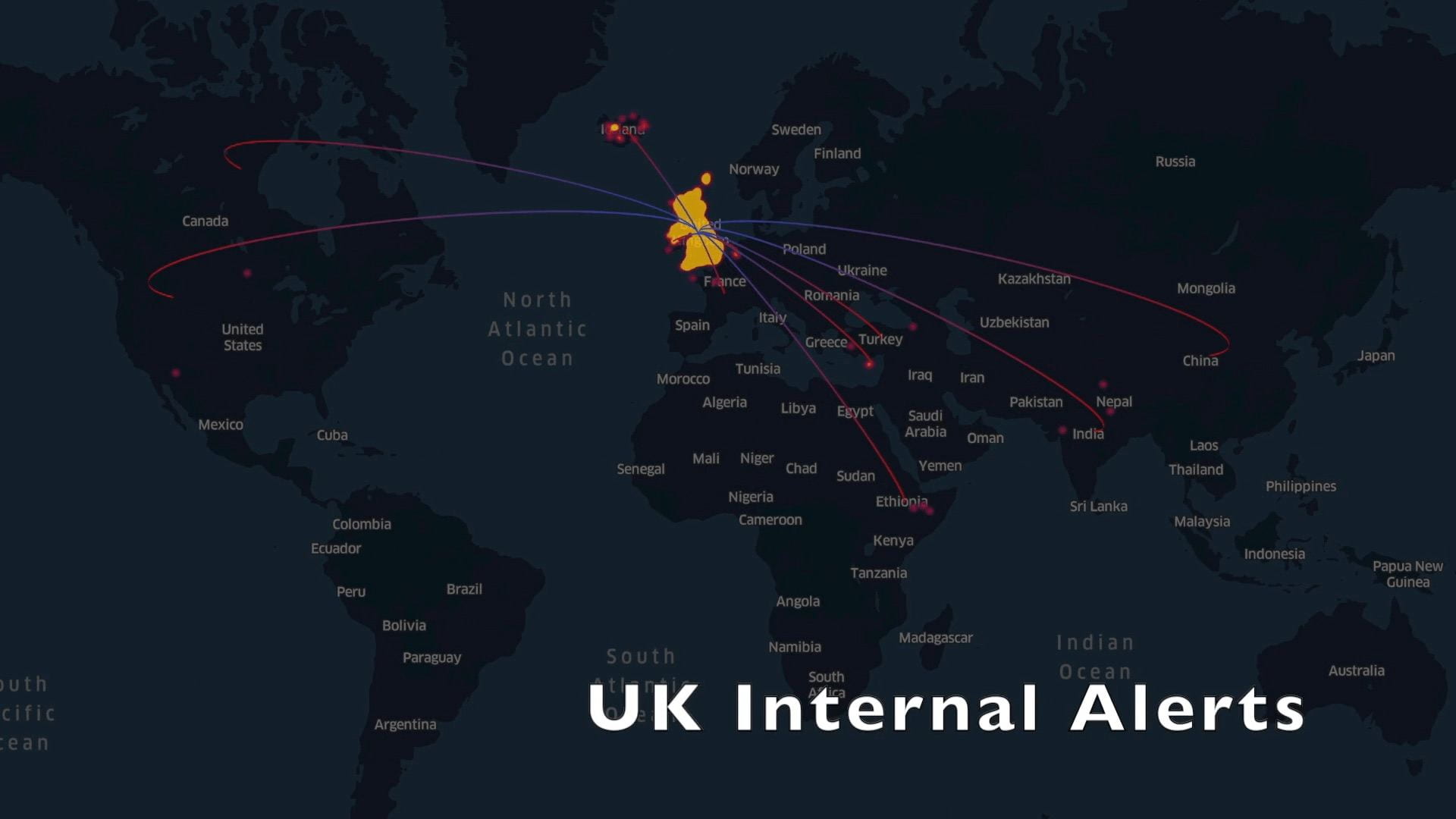
In the first part of the analysis, we exploredcases where food imported to Britainled toan alert being raised. The two biggest sources for such alerts were Britain’s internal alert systems (largely the FSA), and the EU’s Rapid Alert System for Food and Feed (RASFF).
Since Britain is on course tolose access to RASFF-supplied information once Brexit is finalised in early 2021, we created the visualisation below as a comparisonof the FSA and the RASFF in terms of both the numberof alerts raisedand the corresponding food’s origin country for each alert.
Alerts from the EU Alert System
The arcs show the countries of origin ofimports that raised alerts, and the yellow-red density map shows the recordedhazard alert frequency from those origins.Interactive versions ofthe two map instancescan be foundby following these links: RASFF, UK internal alerts.
Alerts from the UK Alert System
If the UK does indeed loseaccess to the RASFF, the loss of food hazards information about our own imports will be tremendous. The burden then falls on the FSA to develop and extend their alert system (which currently focuses very little on internationally supplied food) to bridge this information gap and ensure food safety forgloballyimported goods.As of the time of writing weare unsure what steps are being taken by the FSA, or the government at large, to address this issue.
Post-Brexit Shifts in Food Hazard Threats
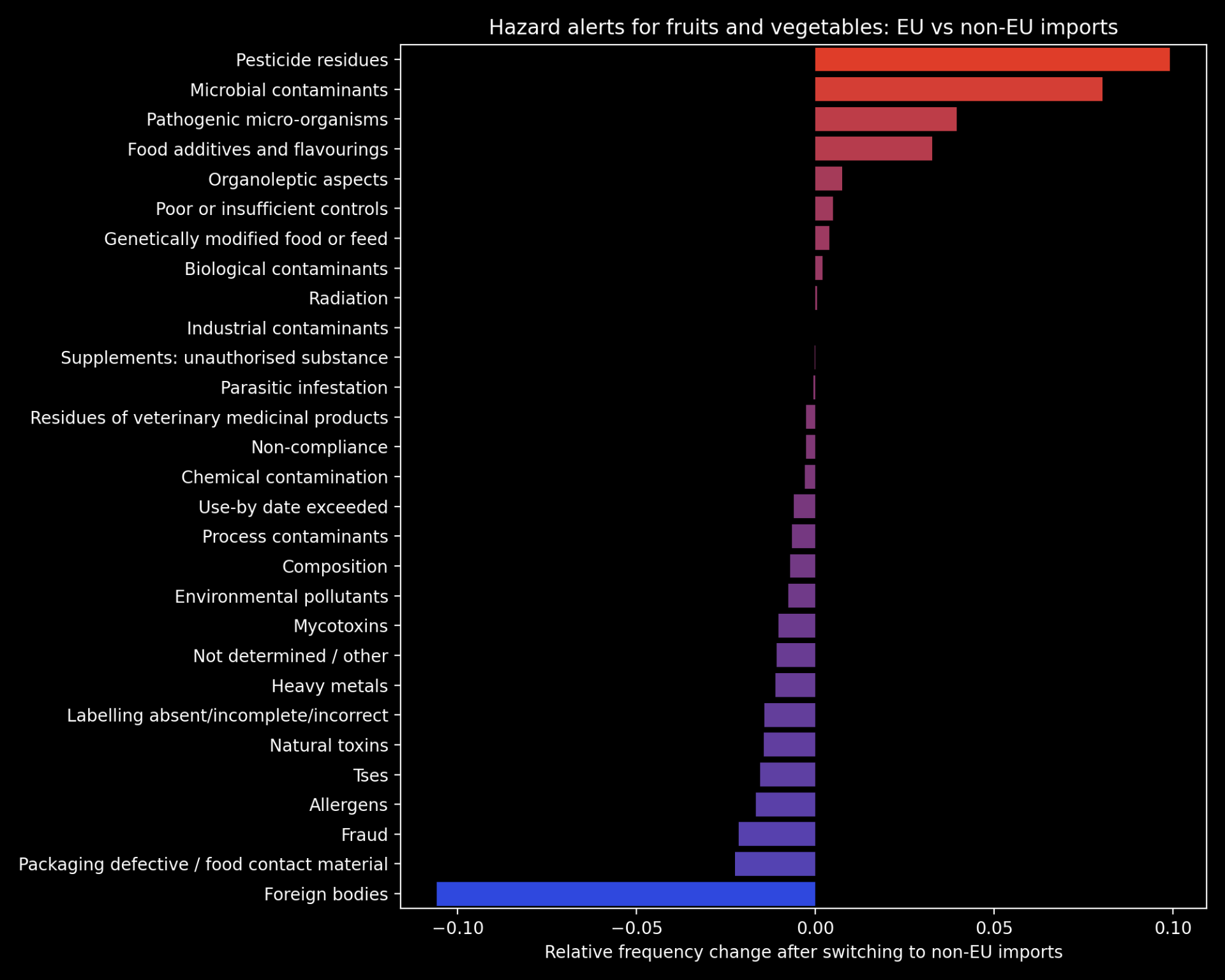
As an extension of this work, we turned our attention to tariffs and the effect they might have on whom Britain chooses to import from. Upon leaving the EU the UK will have to negotiate new trade deals with both EU and non-EU countries.Sincethe cost forEU-produced food is expected to rise for Britain after Brexit, wemayindeed see Britain importing more from outside of the union, which would naturally bring a shift to the make–up of food hazards that our alert systems will need to detect. Anticipating this shift will allow us to better mitigate the accompanying risk if it does begin to materialise.
To this end, we explored the differences in food hazard threats posed by EU vs non-EU suppliers of Britain’s largest class of imported food: fruits and vegetables. The plot below shows the relative change in frequency for each category of food hazard in the case that Britain switched from 100% EU imports of fruit and vegetables to 100% non-EU. The hazard categories that are likely to increase in non-EU imports are highlighted in red. Please note that this is the most extreme case possible and is unlikely to unfold to this extent inreality– this plot is therefore presented as aguide to the different food threats posed by EU vs non-EU imports.
Hazard alerts for fruits and vegetables: EU vs non-EU imports
Our full submission‘Too Much Tooty in the Fruity: Keeping Food Safe in a Post-Brexit Britain’ can be found here, and includes a further breakdown of some of the categories of hazards displayed in the chart above. This work was awarded one of two joint runner-up prizes of the competition, tied with Angharad Stell’sShiny app:‘From a data space to knowledge discovery’. The winner of the competition was Robert Eyre, who producedthis impressive visualization dashboard using D3.The Jean Golding Institute are hosting a showcase event on the 18th November, where all competition entries will be presented.
We would like to thank theJGI for hosting the competition, and our PhD supervisors, Prof. Tom Gaunt and Dr. Ben Elsworth, for encouraging us to enter.
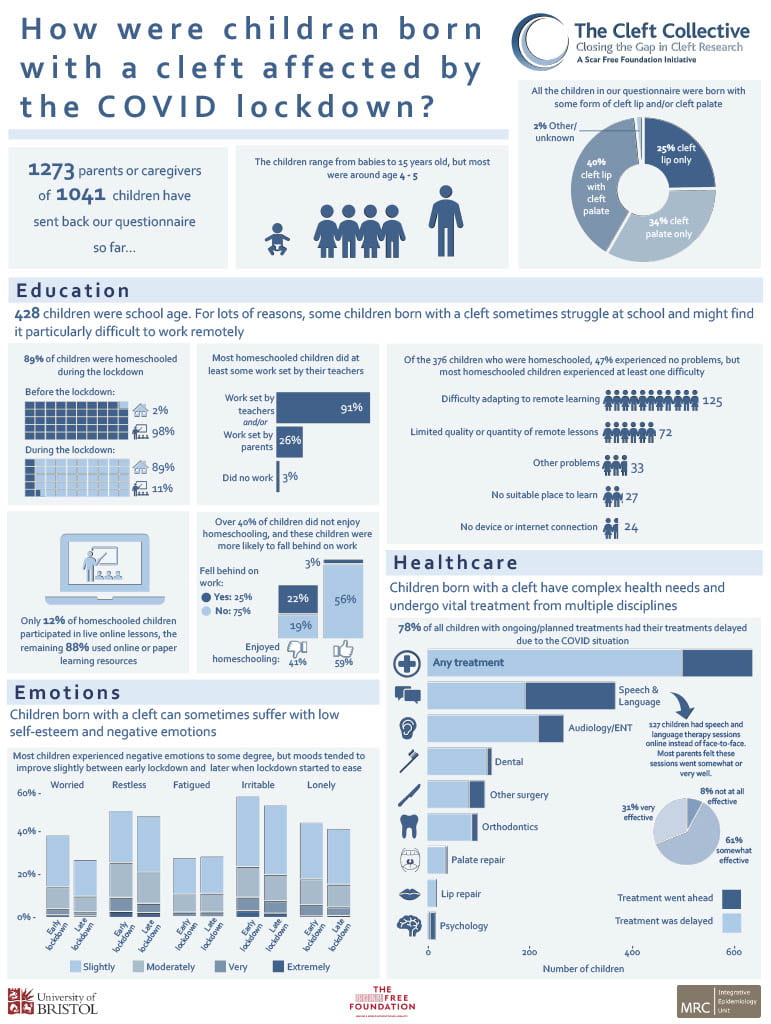
The COVID-19 pandemic has been difficult for many families and there is widespread concern about how the lockdown might have affected children’s health, wellbeing and education. This concern may be even greater for families of children with pediatric health conditions such as cleft lip and/or cleft palate.
The Cleft Collective cohort study, linked to the IEU, is a UK-wide research study of the causes and consequences of being born with a cleft, which is a gap in the lip or roof of the mouth. In response to the COVID-19 lockdown, the Cleft Collective team sent out a questionnaire asking parents about how the lockdown had affected their children’s surgeries and treatments, access to schooling and wellbeing.
The first results are summarised in this infographic, which highlights that many children suffered delays in their surgeries and other health care appointments due to the lockdown. They also struggled with homeschooling, worries and negative emotions.
Through links to the NHS cleft teams and the Cleft Lip and Palate Association charity (CLAPA), the Cleft Collective team are sharing their findings with healthcare professionals to help ensure that children born with a cleft are given appropriate support to help them through this time and to lead happy, healthy childhoods.
The Cleft Collective cohort study is based in the MRC Integrative Epidemiology Unit and funded by the Scar Free Foundation and the University of Bristol. The video below explains more about the study.
Epigenetics can help explain how our genes and environment interact to shape our development. Interest in epigenetics has grown increasingly within the research community, but until now little was known about how epigenetics change over time. We therefore studied changes in our epigenome from birth to late adolescence and created an interactive website inviting other researchers to explore our findings.
What is epigenetics?
The term ‘epigenetics’ refers to the molecular structures around the DNA in our cells, that affect if, when, and how our genes work. Even though nearly every cell in our body contains the exact same copy of DNA, cells can look and function entirely differently. Epigenetics can explain this. For example, every cell in our body has the potential to store fat, but in adipose tissues the cells’ epigenetic structures cause the cells to actually store fat.
Before birth, epigenetics plays a role in the specialization of cells from conception onwards by turning genes ‘on’ and ‘off’. After birth, epigenetics help our body develop even further, and maintain the specialization of our cells. However, the way epigenetics influence how our cells function is not only programmed by our genes, but may also be affected by the environment. Hence, our development and health is shaped by both our genes and our environment. Researchers are therefore trying to measure epigenetic processes to understand the role that epigenetics plays in this process of ‘nurture affecting nature’.
Both nurture and nature influence our health; understanding epigenetics helps us to find out how they might interact.
How can we measure epigenetics?
One of the types of molecular structures that can affect gene functioning is ‘DNA methylation’. Here, a small molecule (a methyl group of one carbon atom bonded to three hydrogen atoms; Figure 1) is attached to the DNA sequence. DNA methylation affects the three-dimensional structure of the DNA and can thereby turn it ‘on’ or ‘off’. DNA methylation can now easily be measured in the lab with the help of micro-chips; very small chips that can detect hundreds of thousands of methylation sites in the genome at a time, from just a small droplet of blood. Such chips are now used in large epidemiological cohorts such as ALSPAC to measure the level of DNA methylation for each of these sites. In epigenome-wide associations studies (EWASs), researchers study the associations between each of these methylation sites and a trait, such as prenatal smoking, BMI, or stress.
Figure 1: DNA sequence with DNA methylation
How does DNA methylation change throughout development?
Until recently, EWASs have mainly been cross-sectional, studying DNA methylation only at one time-point. So, even though research indicates that epigenetics is important in postnatal development, we do not know how true this is for DNA methylation sites measured with these epigenome-wide arrays. Studying a mechanism that supposedly changes over time without knowing how it changes can be problematic: say that we find an association between smoking during pregnancy and DNA methylation at birth, can we still expect this association to be there at a later age? To fully interpret EWAS findings, and to compare research findings between different studies, we need a full understanding of how DNA methylation changes throughout development.
We therefore set out to study DNA methylation from birth to late adolescence, using DNA methylation measured in blood from the participants of ALSPAC in the UK, as well as from participants from another large cohort, the Generation R Study in the Netherlands.
We studied the change in levels of DNA methylation over time as well as variation in this change between individuals. If DNA methylation is indeed mainly linked to the basic developmental stages we go through as we grow up, we would expect methylation changes to be largely consistent between individuals. However, if DNA methylation is affected more by the different environments we live in, and individual health profiles, we would expect a proportion of sites to change differently for different individuals.
Between ALSPAC and Generation R, we created a unique dataset containing over 5,000 samples from about 2,500 participants with DNA methylation measurements at almost half a million methylation sites measured repeatedly at birth, 6 years, 10 years, and at 17 years. With various statistical models we studied different trajectories of change in DNA methylation.
We found change in DNA methylation at just over half of the sites (see for an example Figure 2a). At about a quarter of sites, DNA methylation changed at a different rate for different individuals (Figure 2b). We further saw that sometimes change only happened in a specific time period; for example, only in between birth and the age of 6 years after which DNA methylation remained stable (Figure 2c), and that sometimes differences in the rate of change only started from the age of 9 years (Figure 2d). Last, for less than 1% of the sites on the chromosomes tested (we did exclude the sex chromosomes), we saw that DNA methylation changed differently for boys and girls (Figure 2e).
Figure 2. Different examples of methylation sites, with every graph representing one methylation site with age on the x-axis and level of DNA methylation on the y-axis. Every line represents change in DNA methylation over time for one individual, showing (a) change in DNA methylation, (b) different rates of change for different individuals, (c) change during the first six years of life, (d) different rates of change starting from 9 years of age, (e) different change for boys and girls, and (f) change, but no differences in rate of change in a site associated to prenatal smoking.
How can we use these findings in future research?
These results show that there are sites in the genome for that show change in DNA methylation that is consistent between individuals, as well as sites that change at a different rate for different individuals. We have published the trajectories of change for each methylation site on a publicly available website. This makes it easier for other researchers to find sites that are developmentally important and may be of relevance for health and disease. For example, a methylation site previously associated with prenatal smoking, remained stable over time (Figure 1f), indicating that prenatal influences of smoking may be long-lasting, at least up to adolescence. In the future, we hope to associate traits, such as stress and BMI, to these longitudinal changes, to further our understanding of the developmental nature of DNA methylation and the associated biological pathways leading to health and disease.
1Department of Child and Adolescent Psychiatry/Psychology, Erasmus MC, University Medical Center Rotterdam, Rotterdam, the Netherlands
2 Department of Child and Adolescent Psychiatry/Psychology, Erasmus MC, University Medical Center Rotterdam, Rotterdam, the Netherlands
3 MRC Integrative Epidemiology Unit, Population Health Sciences, Bristol Medical School, University of Bristol, Bristol, UK
4 Department of Psychology, University of Bath, Bath, UK
5 Department of Epidemiology, Erasmus MC, University Medical Center Rotterdam, Rotterdam, the Netherlands
6 Department of Psychology, Institute of Psychology, Psychiatry & Neuroscience, King’s College London, London, UK
Further reading
Mulder, R. H., Neumann, A. H., Cecil, C. A., Walton, E., Houtepen, L. C., Simpkin, A. J., … & Jaddoe, V. W. (2020). Epigenome-wide change and variation in DNA methylation from birth to late adolescence. bioRxiv. (preprint)
As we usher in the era of precision medicine – healthcare tailored to the individual – genetic information is being used to design drugs, tests and medical procedures. While this approach enables physicians to better predict the needs of patients and quickly adopt the most suitable treatment, it should be acknowledged that what is suitable for many, is not suitable for all. Appropriate medical care is linked with ancestry – for example, healthy people with African ancestry naturally exhale less air than reference samples of Europeans, leading to mis-diagnosis for Asthma. For people from Black and Minority Ethnicities, the potential impact of ethnicity is intensely debated in Cancer treatment. Research suggests that lack of BME participation in medical research will lead to poor medication choices, genetic tests being less useful, and any COVID-19 treatments being less well tested.
The World Health Organization has stated that “everyone should have a fair opportunity to attain their full health potential and that no one should be disadvantaged from achieving their potential”. However, systematic discrimination & socio-economic-related disadvantages such as lower education and difficulty accessing high quality jobs are overwhelmingly experienced by non-white people, with statistics showing that 80% of Black African and Caribbean communities are living in England’s most deprived areas (as defined by the Neighbourhood Renewal Fund). These factors contribute to people from those communities receiving worse medical care overall. Beyond this, poor representation in research now can only lead to systematically poorer healthcare in the years to come. In 2009, only 4% of genetic association studies used samples with non-European ancestry. Whilst this rose to almost 20% by 2016, this improvement was largely due to East Asian nations such as Korea, China and Japan initiating their own biobank projects, leaving many ethnicities under-represented. Hence, from a medical genetics perspective, “Black and Minority Ethnicity” (BME) is well defined as “ethnicities without a rich nation to back a representative genetic biobank” and includes African ancestry.
Improving participation of underrepresented populations in Biobanks should make science more useful for all.
Why does biobank representation matter?
Epidemiological comparisons – that is, comparing large numbers of people who develop disease and those that do not – often rely on genetics to infer which behaviours and conditions are causes and which are effects. These analyses use a technique called Mendelian Randomization (MR). MR has demonstrated, for example, that alcohol consumption causally increases body mass and made it clear that even moderate alcohol intake has no beneficial effect on health outcomes. Causal hypotheses are a critical pathway to drug discovery and public health intervention, but are based almost entirely on European populations. Since there are many genes that affect most disease risk and these are of different importance across ancestries, we cannot be certain that the associations found apply to other populations. This urgently needs to be addressed in order to:
promote representative translational research that is relevant to all
reduce bias in the consideration of new health policies that may negatively impact minority populations.
Some populations have increased risk from specific diseases, and many people have ancestry from all over the world, making the categorisation of ‘race’ in medicine of some value but increasingly problematic. The IEU leads work on measuring this ancestry variation, which is important for individuals’ health. Getting at the cause of disease is key for understanding the effects of genes on disease risk and traits. Data on varied ethnicities is valuable for science, simply by showing us more variation. Traits such as height, weight and pre-inclination for education may not be directly related to ethnicity, but data from varied ancestries still helps to separate genetic cause from effect. Paradoxically, the least available data on African ancestry is particularly valuable scientifically, due to the lack of variation in the population that came out-of-africa around 50,000 years ago.
Science and the public improving representation together
Acknowledgement of this deficit is becoming more widespread, and the Black Lives Matter movement has refocused attention on representation in science, but the solution remains undetermined. How do we in the science and research community push for better diversity and representation in our resources? Biobanks operate on a consensual ‘opt in, opt out’ system and tend to favour certain groups. In 2016 the Financial Times generalised the participants of UK Biobank and “healthy, wealthy and white”, but why do so many more individuals from this demographic ‘opt in’? In 2018 Prictor et al theorised that BME groups may experience more barriers to participation such as location, cultural sensitivities around human tissue, and issues of literacy and language. However, given the history of the relationship between the research community and minority groups, seen in cases such as the Tuskegee Study, it is easy to see why BME populations might be less inclined to participate, if invited.
Although there is still need for considerable change, several recent developments will help, including the China Kadoori Biobank, the ancestrally diverse US-based Million Veterans program, and many others. However, given restrictions on privacy and reporting methods, these biobanks are hard to compare. Currently the IEU is part of a multi-national effort to develop tools to get the best science possible out of these comparisons, whilst simultaneously respecting privacy and data security issues. The IEU has been collaborating with various research groups across the world to make our research more reproducible. Building tools that work at scale is a challenge encompassing Mathematics, Statistics, Computer Science, Engineering, Genomics and Epidemiology, but this work is paving the way to promoting representative research that is inclusive and applicable for all.
The COVID-19 pandemic caused by the SARS-COV2 virus in 2020 has so far resulted in a heavy death toll and caused unprecedented disruption worldwide. Many countries have opted for drastic measures and even full lockdowns of all but essential services to slow the spread of disease and to stop health care systems becoming overwhelmed. However, whilst lockdowns happened fast and were well adhered to in most countries, coming out of lockdown is proving to be more challenging. Policymakers have been trying to balance relaxing restriction measures with keeping virus transmission low. One of the most controversial aspects has been when and how to reopen schools.
Many parents and teachers are asking: Are schools safe?
The answer to this question depends on how much risk an individual is prepared to accept – schools have never been completely “safe”. Also, in the context of this particular pandemic, the risk from COVID-19 to an individual varies substantially by age, sex and underlying health status. However, from a historical context, the risk of death from contracting an infectious disease in UK schools (even in the era of COVD-19) is very low compared to just 40 years ago, when measles, mumps, rubella and whooping cough were endemic in schools. Similarly, from a global perspective UK schools are very safe – in Malawi, for example, the mortality rate for teachers is around five times higher than in the UK, with tuberculosis causing more than 25% of deaths among teachers.
In this blog post we use data on death rates to discuss safety, because there is currently better evidence on death rates by occupational status than, for example, infection rates. This is because death rates related to COVID-19 have been consistently reported by teh Office for National Statistics, whereas data on infection rates depends very much on the level of testing in the community (which has changed over time and differs by region).
Risks to children
Thankfully the risk of serious disease and death to children throughout the pandemic, across the UK and globally, has been low. Children (under 18 years) make up around 20% of the UK population, but account for only around 1.5% of those hospitalised with COVID-19. This age group have had better outcomes according to all measures compared to adults. As of the 12th June 2020, there have been 6 deaths in those with COVID-19 among those aged under 15 years across England and Wales. Whilst extremely sad, these deaths represent a risk of around 1 death per 2 million children. To place this in some kind of context, the number of deaths expected due to lower respiratory tract infections among this age group in England and Wales over a 3 month period is around 50 and 12 children would normally die due to road traffic accidents in Great Britain over a 3-month period.
Risks to teachers
Our previous blog post concluded that based on available evidence the risk to teachers and childcare workers within the UK from Covid-19 did not appear to be any greater than for any other group of working age individuals. It considered mortality from COVID-19 among teachers and other educational professionals who were exposed to the virus prior to the lockdown period (23rd March 2020) and had died by the 20th April 2020 in the UK. This represents the period when infection rates were highest, and when children were attending school in large numbers. There were 2,494 deaths among working-age individuals up to this date, and we found that the 47 deaths among teachers over this period represented a similar risk to all professional occupations – 6.7 (95% CI 4.1 to 10.3) per 100,000 among males and 3.3 (95% CI 2.0 to 4.9) per 100,000 among females.
The Office for National Statistics (ONS) has since updated the information on deaths according to occupation to include all deaths up to the 25th May 2020. The new dataset includes a further 2,267 deaths among individuals with COVID-19. As the number of deaths had almost doubled during this extended period, so too had the risk. A further 43 deaths had occurred among teaching and education professionals, bringing the total number of deaths involving COVID-19 among this occupational group to 90. It therefore appears that lockdown (during which time many teachers have not been in school) has not had an impact on the rate at which teachers have been dying from COVID-19.
As before, COVID-19 risk does not appear greater for teachers than other working age individuals
The revised risk to teachers of dying from COVID-19 remains very similar to the overall risk for all professionals at 12.9 (95% CI 9.3 to 17.4) per 100,000 among all male teaching and educational professionals and 6.0 (95% CI 4.2 to 8.1) per 100,000 among all females, compared with 11.6 (95%CI 10.2 to 13.0) per 100,000 and 8.0 (95%CI 6.8 to 9.3) per 100,000 among all male and female professionals respectively. It is useful to look at the rate at which we would normally expect teaching and educational professionals to die during this period, as this tells us by how much COVID-19 has increased mortality in this group. The ONS provide this in the form of average mortality rates for each occupational group for same 11 week period over the last 5 years. The mortality due to COVID-19 during this period represents 33% for males and 19% for females of their average mortality over the last 5 years for the same period. For male teaching and educational professionals, the proportion of average mortality due to COVID-19 is very close to the value for all working-aged males (31%) and all male professionals (34%). For females the proportion of average mortality due to COVID-19 is lower than for all working-aged females (25%) and for female professionals (25%). During the pandemic period covered by the ONS, there was little evidence that deaths from all causes among the group of teaching and educational professionals were elevated above the 5-year average for this group.
Teaching is a comparatively safe profession
It is important to note that according to ONS data on adults of working age (20-59 years) between 2001-2011, teachers and other educational professionals have low overall mortality rates compared with other occupations (ranking 3rd safest occupation for women and 6th for men). The same study found a 3-fold difference between annual mortality among teachers and among the occupational groups with the highest mortality rates (plant and machine operatives for women and elementary construction occupations among men). These disparities in mortality from all causes also exist in the ONS data covering the COVID-19 pandemic period, but were even more pronounced with a 7-fold difference between males teaching and educational professionals and male elementary construction occupations, and a 16-fold difference between female teachers and female plant and machine operatives.
There is therefore currently no indication that teachers have an elevated risk of dying from COVID-19 relative to other occupations, and despite some teachers having died with COVID19, the mortality rate from all causes (including COVID19) for this occupational group over this pandemic period is not substantially higher than the 5 year average.
Will reopening schools increase risks to teachers?
One could argue that the risk to children and teachers has been low because schools were closed for much of the pandemic, and children have largely been confined to mixing with their own households, so that when schools open fully risk will increase. However, infection rates in the community are now much lower than they were at their peak, when schools were fully open to all pupils without social distancing. Studies which have used contract tracing to determine whether infected children have transmitted the disease to others have consistently shown that they have not, although the number of cases included has been small, and asymptomatic children are often not tested. Modelling studies estimate that even if schools fully reopen without social distancing, this is likely to have only modest effects on virus transmission in the community. If infection levels can be controlled – for example by testing and contact tracing efforts – and cases can be quickly isolated, then we believe that schools pose a minimal risk in terms of the transmission of COVID, and to the health of teachers and children. Furthermore, the risk is likely to be more than offset by the harms caused by ongoing disruption to children’s educational opportunities.
Sarah Lewis is a Senior Lecturer in Genetic Epidemiology in the department of Population Health Sciences, and is an affiliated member of the MRC Integrative Epidemiology Unit (IEU), University of Bristol.
Marcus Munafo is a Professor of Biological Psychology, in the School of Psychology Science and leads theCauses, Consequences and Modification of Health Behaviours programme of research in the IEU, University of Bristol.
George Davey Smith is a Professor of Clinical Epidemiology, and director of the MRC IEU, University of Bristol.
The manufacturing or importing of packs of cigarettes with fewer than 20 cigarettes per pack was prohibited in the UK when the EU Tobacco Products Directive and standardised packaging legislation were fully implemented in May 2017. This change was aimed at reducing the affordability of cigarettes and thereby discouraging young people from smoking. This directive also required the removal of branding and established a standard shape and dark green colour for packaging, including pictorial health warnings, which prevented the use of packaging for promotion and reduced its appeal.
However, the tobacco industry has been able to exploit loopholes in recent packaging regulations, including the absence of a regulated maximum pack size, by introducing non-standard and larger pack sizes to the market to distinguish products. This is a public health concern given evidence that larger pack sizes are linked to increased smoking, and could undermine existing tobacco control success.
Evidence shows that larger pack sizes are linked to increased smoking.
In a recent Addiction Opinion and Debate paper, we proposed that a cap on cigarette pack size should be introduced; a pragmatic solution would be to permit only a single pack size of 20, which is now the minimum in many countries. This approach would reduce the number of cigarettes in packs in several countries such as Australia – where packs up to sizes of 50 are available – and prevent larger sizes being introduced elsewhere.
Capping cigarette pack size therefore has the potential to both reduce smoking and prevent increased smoking. While the health benefits of reducing smoking alone are small, it may have important indirect effects on health through its role in facilitating quitting. Those smoking fewer cigarettes per day are more likely to attempt to quit and succeed in doing so. Trials of smoking-reduction interventions have also found that these can lead to increased quitting when combined with nicotine replacement therapy.
Our Opinion and Debate paper drew on evidence from a range of sources including industry documents and analyses, population surveys, intervention trials and Mendelian randomization analyses. Together these suggest that consumption increases with larger pack size, and cessation increases with reduced consumption. However, direct experimental evidence is not currently available to determine whether pack size influences the amount of tobacco consumed, or whether the association is due to other factors.
People who want to quit may be using smaller packs as a method of self-control, and smokers who successfully cut down and later quit may be more motivated to do so. Cost is also an important factor and larger packs may be linked to increased smoking because they have a lower cost per cigarette. Further research is needed to determine whether the associations between pack size, smoking and cessation are causal to estimate the impact of policies to cap cigarette pack size.
Commentaries on our Opinion and Debate paper, published in the May 2020 Issue of Addiction highlight the need to understand the mechanisms for the associations observed between pack size and smoking in order to identify the optimal cigarette pack size. Although mandating packs of 20 is a pragmatic approach, pack size regulation needs to achieve a compromise between tobacco affordability and smokers’ self-regulation. Nevertheless, the policy debate should start now to address this neglected aspect of tobacco control.
To find out more visit the Behaviour Change by Design website or follow us on Twitter @BehavChangeDsgn @BristolTARG
Gareth J Griffith, Gibran Hemani, Annie Herbert, Giulia Mancano, Tim Morris, Lindsey Pike, Gemma C Sharp, Matt Tudball, Kate Tilling and Jonathan A C Sterne, together with the authors of a preprint on collider bias in COVID-19 studies.
All authors are members of the MRC Integrative Epidemiology Unit at the University of Bristol. Jonathan Sterne is Director of Health Data Research UK South West
Among successful actors, being physically attractive is inversely related to being a good actor. Among American college students, being academically gifted is inversely related to being good at sport.
Among people who have had a heart attack, smokers have better subsequent health than non-smokers. And among low birthweight infants, those whose mothers smoked during pregnancy are less likely to die than those whose mothers did not smoke.
These relationships are not likely to reflect cause and effect in the general population: smoking during pregnancy does not improve the health of low birthweight infants. Instead, they arise from a phenomenon called ‘selection bias’, or ‘collider bias’.
Understanding selection bias
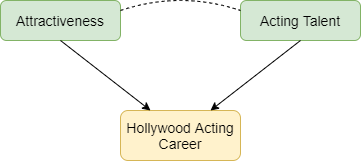
Selection bias occurs when two characteristics influence whether a person is included in a group for which we analyse data. Suppose that two characteristics (for example, physical attractiveness and acting talent) are unrelated in the population but that each causes selection into the group (for example, people who have a successful Hollywood acting career). Among individuals with a successful acting career we will usually find that physical attractiveness will be negatively associated with acting talent: individuals who are more physically attractive will be less talented actors (Figure 1). Selection bias arises if we try to infer a cause-effect relationship between these two characteristics in the selected group. The term ‘collider bias’ refers to the two arrows indicating cause and effect that ‘collide’ at the effect (being a successful actor).
Figure 1: Selection effects exerted on successful Hollywood actors. Green boxes highlight characteristics that influence selection. Yellow boxes indicate the variable selected upon. Arrows indicate causal relationships: the dotted line indicates a non-causal induced relationship that arises because of selection bias.
Figure 2 below explains this phenomenon. Each point represents a hypothetical person, with their level of physical attractiveness plotted against their level of acting talent. In the general population (all data points) an individual’s attractiveness tells us nothing about their acting ability – the two characteristics are unrelated. The red data points represent successful Hollywood actors, who tend to be more physically attractive and to be more talented actors. The blue data points represent other people in the population. Among successful actors the two characteristics are strongly negatively associated (green line), solely because of the selection process. The direction of the bias (whether it is towards a positive or negative association) depends on the direction of the selection processes. If they act in the same direction (both positive or both negative) the bias will usually be towards a negative association. If they act in opposite directions the bias will usually be towards a positive association.
Figure 2: The effect of sample selection on the relationship between attractiveness and acting talent. The green line depicts the negative association seen in successful actors.
Why is selection bias important for COVID-19 research?
In health research, selection processes may be less well understood, and we are often unable to observe the unselected group. For example, many studies of COVID-19 have been restricted to hospitalised patients, because it was not possible to identify all symptomatic patients, and testing was not widely available in the early phase of the pandemic. Selection bias can seriously distort relationships of risk factors for hospitalisation with COVID-19 outcomes such as requiring invasive ventilation, or mortality.
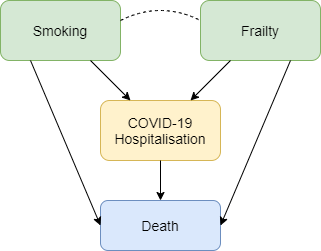
Figure 3 shows how selection bias can distort risk factor associations in hospitalised patients. We want to know the causal effect of smoking on risk of death due to COVID-19, and the data available to us is on patients hospitalised with COVID-19. Associations between all pairs of factors that influence hospitalisation will be distorted in hospitalised patients. For example, if smoking and frailty each make an individual more likely to be hospitalised with COVID-19 (either because they influence infection with SARS-CoV-2 or because they influence COVID-19 disease severity), then their association in hospitalised patients will usually be more negative than in the whole population. Unless we control for all causes of hospitalisation, our estimate of the effect of any individual risk factor on COVID-19 mortality will be biased. For example, it would be unsurprising that within hospitalised patients with COVID-19 we observe that smokers have better health than non-smokers because they are likely to be younger and less frail, and therefore less likely to die after hospitalisation. But that finding may not reflect a protective effect of smoking on COVID-19 mortality in the whole population.
Figure 3: Selection effects on hospitalisation with COVID-19. Box colours are as in Figure 1. Blue boxes represent outcomes. Arrows indicate causal relationships, the dotted line indicates a non-causal induced relationship that arises because of selection bias.
Selection bias may also be a problem in studies based on data from participants who volunteer to download and use COVID-19 symptom reporting apps. People with COVID-19 symptoms are more likely to use the app, and so are people with other characteristics (younger people, people who own a smartphone, and those to whom the app is promoted on social media). Risk factor associations within app users may therefore not generalise to the wider population.
What can be done?
Findings from COVID-19 studies conducted in selected groups should be interpreted with great caution unless selection bias has been explicitly addressed. Two ways to do so are readily available. The preferred approach uses representative data collection for the whole population to weight the sample and adjust for the selection bias. In absence of data on the whole population, researchers should conduct sensitivity analyses that adjust their findings based on a range of assumptions about the selection effects. A series of resources providing further reading, and tools allowing researchers to investigate plausible selection effects are provided below.
Dahabreh IJ and Kent DM. Index Event Bias as an Explanation for the Paradoxes of Recurrence Risk Research. JAMA 2011; 305(8): 822-823.
Griffith, Gareth, Tim M. Morris, Matt Tudball, Annie Herbert, Giulia Mancano, Lindsey Pike, Gemma C. Sharp, Jonathan Sterne, Tom M. Palmer, George Davey Smith, Kate Tilling, Luisa Zuccolo, Neil M. Davies, and Gibran Hemani. Collider Bias undermines our understanding of COVID-19 disease risk and severity.Interactive App 2020 http://apps.mrcieu.ac.uk/ascrtain/
Since the pandemic started, communities have been mobilising to help each other; from shopping for elderly neighbours, to offering to offering a friendly face or other support. Mutual aid networks have sprung up all over the country, and neighbours who hadn’t previously spoken have been introduced to each other via street–level WhatsApp groups. But the degree to which offers of help are matching up with the need for help has been unknown, and this poses a problem for organisations who need to make decisions about where they should target limited resources.
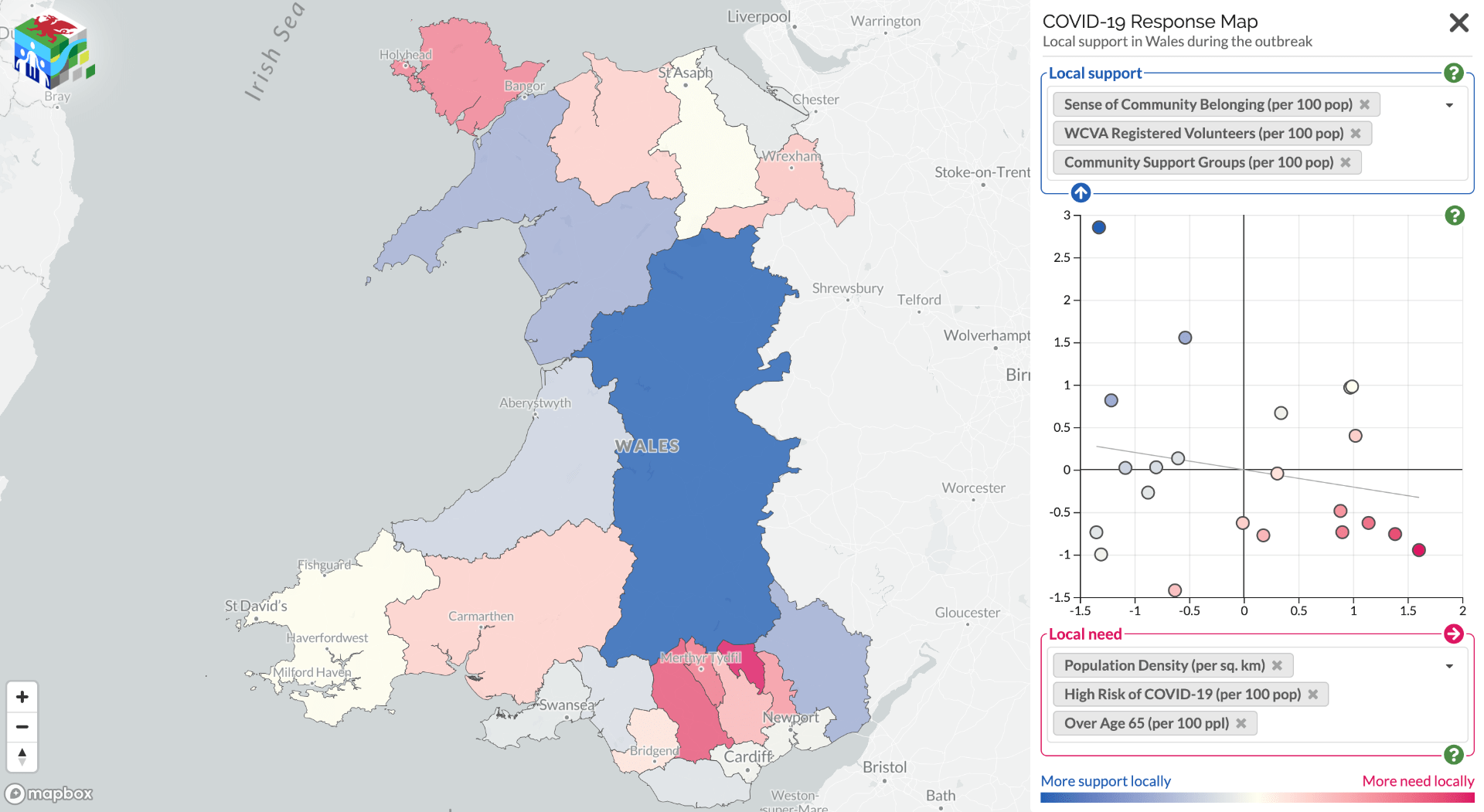
Community support can offer a protective factor against adverse events. Some areas are more vulnerable than others, but knowing which areas are most likely to have a mismatch between support needed and support offered is difficult. To address this issue, a collaboration between the Public Health Wales Research & Evaluation Division and the Dynamic Genetics lab, part of the MRC Integrative Epidemiology Unit at the University of Bristol and supported by the Alan Turing Institute, has mapped these support offers and needs.
Using data from Wales Council for Voluntary Action, COVID-19 Mutual Aid, Welsh Government Statistics and Research, the Office for National Statistics, and social media the project team have created alive map that highlights the areas where further support for communities may be needed. It shows data on support factors, such as number of registered volunteers and population density, against risks, such as demographics, levels of deprivation, and internet access. It aims to inform the responses of national and local government, as well as support providers in Wales.
The site also provides the links to local community groups identified helping to raise awareness of the support available locally.
This map is part of an effort to better understand which communities have better community cohesion and organisation. We are keen to find out your views on how this can be more useful, or other community mobilisation data sources which could be included. Please contact Oliver or Nina with your comments:
If you are a community group and want to be included, please register your group with Covid-19 Mutual Aid (https://covidmutualaid.org/).
The code used to create the map has been released openly on GitHub (https://github.com/DynamicGenetics/COVID-19-Community-Response) so that it can be reproduced. Full information on the sources of data on vulnerability and community support are documented on the Open Science Framework (https://osf.io/c48hw/) and the map will be updated as new information becomes available.
Due to the SARS-CoV-2 pandemic schools across the United Kingdom were closed to all but a small minority of pupils (children of keyworkers and vulnerable children) on the 20th March 2020, with some schools reporting as few as 5 pupils currently attending. The UK government have now issued guidance that primary schools in England should start to accept pupils back from the 1st June 2020 with a staggered return, starting with reception, year 1 and year 6.
Concern from teachers’ unions
This has prompted understandable concern from the teachers’ unions, and on the 13th May, nine unions which represent teachers and education professionals signed a joint statement calling on the government to postpone reopening school on the 1st June, “We all want schools to re-open, but that should only happen when it is safe to do so. The government is showing a lack of understanding about the dangers of the spread of coronavirus within schools, and outwards from schools to parents, sibling and relatives, and to the wider community.” At the same time, others have suggested that the harms to many children due to neglect, abuse and missed educational opportunity arising from school closures outweigh the small increased risk to children, teachers and other adults of catching the virus.
What risk does Covid19 pose to children?
Weighing up the risks to children and teachers
So what do we know about the risk to children and to teachers? We know that children are about half as likely to catch the virus from an infected person as adults, and if they do catch the virus they are likely to have only mild symptoms. The current evidence, although inconclusive, also suggests that they may be less likely to transmit the virus than adults. However, teachers have rightly pointed out that there is a risk of transmission between the teachers themselves and between parents and teachers.
The first death from COVID-19 in England was recorded at the beginning of March 2020 and by the 8th May 2020 39,071 deaths involving COVID-19 had been reported in England and Wales. Just three of these deaths were among children aged under 15 years and only a small proportion of the deaths (4416 individuals, 11.3%) were among working aged people. Even among this age group risk is not uniform; it increases sharply with age from 2.6 in 100,000 for 25-44 years olds with a ten fold increase to 26 in 100,000 individuals for those aged 45-64.
Risks to teachers compared to other occupations
In addition, each underlying health condition increases the risk of dying from COVID-19, with those having at least 1 underlying health problem making up most cases. The Office for National Statistics in the UK have published age standardised deaths by occupation for all deaths involving COVID-19 up to the 20th April 2020. Most of the people dying by this date would have been infected at the peak of the pandemic in the UK prior to the lockdown period. They found that during this period there were 2494 deaths involving Covid-19 in the working age population. The mortality rate for Covid-19 during this period was 9.9 (95% confidence intervals 9.4-10.4) per 100,000 males and 5.2 (95%CI 4.9-5.6) per 100,000 females, with Covid-19 involved in around 1 in 4 and 1 in 5 of all deaths among males and females respectively.
Amongst teaching and education professionals (which includes school teachers, university lecturers and other education professionals) a total of 47 deaths (involving Covid-19) were recorded, equating to mortality rates of 6.7 (95%CI 4.1-10.3) per 100,000 among males and 3.3 (95%CI 2.0-4.9) per 100,000 among females, which was very similar to the rates of 5.6 (95%CI 4.6-6.6) per 100,000 among males and 4.2(95%CI 3.3-5.2) per 100,000 females for all professionals. The mortality figures for all education professionals includes 7 out of 437000 (or 1.6 per 100,000 teachers) primary and nursery school teachers and 17 out of 395000 (or 4.3 per 100,000 teachers) secondary school teachers. A further 20 deaths occurred amongst childcare workers giving a mortality rate amongst this group of 3.4 (95%CI=2.0-5.5) per 100,000 females (males were highly underrepresented in this group), this is in contrast to rates of 6.5 (95%CI=4.9-9.1) for female sales assistants and 12.7(95%CI= 9.8-16.2) for female care home workers.
Covid-19 risk does not appear greater for teachers than other working age individuals
In summary, based on current evidence the risk to teachers and childcare workers within the UK from Covid-19 does not appear to be any greater than for any other group of working age individuals. However, perceptions of elevated risk may have occurred, prompting some to ask “Why are so many teachers dying?” due to the way this issue is portrayed in the media with headlines such as “Revealed: At least 26 teachers have died from Covid-19” currently on the https://www.tes.com website. This kind of reporting, along with the inability of the government to communicate the substantial differences in risk between different population groups – in particular according to age – has caused understandable anxiety among teachers. Whilst, some teachers may not be prepared to accept any level of risk of becoming infected with the virus whilst at work, others may be reassured that the risk to them is small, particularly given that we all accept some level of risk in our lives, a value that can never be zero.
Likely impact on transmission in the community is unclear
As the majority of parents or guardians of school aged children will be in the 25-45 age range, the risk to them is also likely to be small. Questions remain however around the effect of school openings on transmission in the community and the associated risk. This will be affected by many factors including the existing infection levels in the community, the extent to which pupils, parents and teachers are mixing outside of school (and at the school gate) and mixing between individuals of different age groups. This is the primary consideration of the government Scientific Advisory Group for Emergencies (SAGE) who are using modelling based on a series of assumptions to determine the effect of school openings on R0.
Sarah Lewis is a Senior Lecturer in Genetic Epidemiology in the department of Population Health Sciences, and is an affiliated member of the MRC Integrative Epidemiology Unit (IEU), University of Bristol
George Davey Smith is a Professor of Clinical Epidemiology, and director of the MRC IEU, University of Bristol
Marcus Munafo is a Professor of Biological Psychology, in the School of Psychology Science and leads theCauses, Consequences and Modification of Health Behaviours programme of research in the IEU, University of Bristol.
The COVID-19 pandemic is proving to be a period of great uncertainty. Will we get it? If we get it, will we show symptoms? Will we have to go to hospital? Will we be ok? Have we already had it?
These questions are difficult to answer because, currently, not much is known about who is more at risk of being infected by coronavirus, and who is more at risk of being seriously ill once infected.
Researchers, private companies and government health organisations are all generating data to help shed light on the factors linked to COVID-19 infection and severity. You might have seen or heard about some of these attempts, like the COVID-19 Symptom Tracker app developed by scientists at King’s College London, and the additional questions being sent to people participating in some of the UK’s biggest and most famous health studies, like UK Biobank and the Avon Longitudinal Study of Parents and Children (ALSPAC).
These valuable efforts to gather more data will be vital in providing scientific evidence to support new public health policies, including changes to the lockdown strategy. However, it’s important to realise that data gathered in this way is ‘observational’, meaning that study participants provide their data through medical records or questionnaires but no experiment (such as comparing different treatments) is performed on them. The huge potential impact of COVID-19 data collection efforts makes it even more important to be aware of the difficulties of using observational data.
Image by Engin Akyurt from Pixabay
Correlation does not equal causation (the reason observational epidemiology is hard)
These issues boil down to one main problem with observational data: that it is difficult to tease apart correlation from causation.
There are lots of factors that correlate but clearly do not actually have any causal effect on each other. Just because, on average, people who engage in a particular behaviour (like taking certain medications) might have a higher rate of infection or severe COVID-19 illness, it doesn’t necessarily mean that this behaviour causes the disease. If the link is not causal, then changing the behaviour (for example, changing medications) would not change a person’s risk of disease. This means that a change in behaviour would provide no benefit, and possibly even harm, to their health.
This illustrates why it’s so important to be sure that we’re drawing the right conclusions from observational data on COVID-19; because if we don’t, public health policy decisions made with the best intentions could negatively impact population health.
Why COVID-19 research participants are not like everyone else
One particular issue with most of the COVID-19 data collected so far is that the people who have contributed data are not a randomly drawn or representative sample of the broader general population.
Only a small percentage of the population are being tested for COVID-19, so if research aims to find factors associated with having a positive or negative test, the sample is very small and not likely to be representative of everyone else. In the UK, people getting the test are likely to be hospital patients who are showing severe symptoms, or healthcare or other key workers who are at high risk of infection and severe illness due to being exposed to large amounts of the virus. These groups will be heavily over-represented in COVID-19 research, and many infected people with no or mild symptoms (who aren’t being tested) will be missed.
Aside from using swab tests, researchers can also identify people who are very likely to have been infected by asking about classic symptoms like a persistent dry cough and a fever. However, we have to consider that people who take part in these sorts of studies are also not necessarily representative of everyone else. For example, they are well enough to fill in a symptom questionnaire. They also probably use social media, where they likely found out about the study. They almost certainly own a smartphone as they were able to download the COVID-19 Symptom Tracker app, and they are probably at least somewhat interested in their health and/or in scientific research.
Why should we care about representativeness?
The fact that people participating in COVID-19 research are not representative of the whole population leads to two problems, one well-known and one less well-known.
Firstly, as often acknowledged by researchers, research findings might not be generalisable to everyone in the population. Correlations or causal associations between COVID-19 and the characteristics or behaviours of research participants might not exist amongst the (many more) people who didn’t take part in the research, but only in the sub-group who participated. So the findings might not translate to the general population: telling everyone to switch up their medications to avoid infection may only work for some people who are like those studied.
But there is a second problem, called ‘collider bias’ (sometimes also referred to using other names such as selection bias or sampling bias), that is less well understood and more difficult to grasp. Collider bias can distort findings so that certain factors appear related even when there is no relationship in the wider population. In the case of COVID-19 research, relationships between risk factors and infection (or severity of infection) can appear related when no causal effect exists, even within the sample of research participants.
As an abstract example, consider a private school where pupils are admitted only if they have either a sports scholarship or an academic scholarship. If a pupil at this school is not good at sports, we can deduce that they must be good at academic work. This correlation between being poor at sports but being good academically doesn’t exist in the real world outside of this school, but in the sample of school pupils, it appears. And so, with COVID-19 research, in the sample of people included in a COVID-19 dataset (e.g. people who have had a COVID-19 test), two factors that influence inclusion (e.g. having COVID-19 symptoms that were severe enough to warrant hospitalisation, and taking medications for a health condition that puts you at high risk of dying from COVID-19) would appear to be associated, even when they are not. That is, to be in the COVID-19 dataset (to be tested), people are likely to have had either more severe symptoms or to be on medication. The erroneous conclusion would follow that changing one factor (e.g. changing or stopping medications) would affect the other (i.e. lower the severity of COVID-19). Because symptom severity is related to risk of death, stopping medication would appear to reduce the chance of death. As such, any resulting changes to clinical practice would be ineffective or even harmful.
Policymaking is a complex process at the best of times, involving balancing evidence from research, practice, and personal experience with other constraints and drivers, such as resource pressures, politics, and values. Add into that the challenge of making critical decisions with incomplete information under intense time pressure, and the need for good quality evidence becomes even more acute. The expertise of statisticians, who can double check analyses and ensure that conclusions are as robust as possible, should be a central part of the decision making process at this time – and especially to make sure that erroneous conclusions arrived at as a result of collider bias do not translate into harmful practice for people with COVID-19.
The main aim of this blog post was to highlight the issue of collider bias, which is notoriously tricky to grasp. We hope we’ve done this but would be interested in your comments.
For those looking for more information, read on to discover some of the statistical methods that can be used to address collider bias….
Now we know collider bias is a problem: how do we fix it?
It is important to consider the intricacies of observational data and highlight the very real problems that can arise from opportunistically collected data. However, this needs to be balanced against the fact that we are in the middle of a pandemic, that important decisions need to be made quickly, and this data is all we have to guide decisions. So what can we do?
There are a few strategies, developed by statisticians and other researchers in multiple fields, that should be considered when conducting COVID-19 research:
Estimate the extent of the collider bias:
o Think about the profile of people in COVID-19 samples – are they older/younger or more/less healthy than individuals in the general population?
o Are there any unexpected correlations in the sample that ring alarm bells?
Try to balance out the analysis by ‘weighting’ individuals, so that people from under-represented groups count more than people from over-represented groups.
Carry out additional analysis, known as ‘sensitivity analysis’, to assess the extent to which plausible patterns of sample selection could alter measured associations.
For those who would like to read even more, here’s a pre print on collider bias published by our team: